© Wuyuhang, 2024. All rights reserved. This article is entirely the work of Wuyuhang from the University of Manchester. It may not be reproduced, distributed, or used without explicit permission from the author. For inquiries, please contact me at yuhang.wu-4 [at] postgrad.manchester.ac.uk.
Background
在当前的数字时代,非结构化数据的数量正以惊人的速度增长,已经成为信息存储和传输的主要形式。研究表明,全球超过80%的数据是以非结构化形式存在的,其中绝大部分是文本数据。这些数据广泛分布于各行各业,从法律文档、学术论文到企业财报、社交媒体内容,几乎无处不在。然而,尽管这些非结构化文本数据为信息检索和知识发现提供了广阔的空间,如何有效地处理和利用这些数据,仍然是一个尚未完全解决的挑战。
检索增强生成(Retrieval-Augmented Generation, RAG)技术结合了检索系统与大型语言模型(LLM)的优势,能够在信息生成过程中参考外部知识库,从而显著提升生成内容的准确性和相关性。RAG技术特别擅长处理需要丰富背景信息的复杂查询,因为它能够从大规模数据集中快速检索出相关信息,并通过LLM进行高质量的内容生成。这种方法已经在多个领域得到了广泛应用,尤其是在需要即时生成高精度回答的场景中。
我们此前在结构化表格数据的处理方面取得了显著进展,特别是通过TableRAG方法,成功优化了从结构化表格数据中检索和生成信息的过程。TableRAG通过增强RAG模型,提升了从表格数据中获取信息的效率和准确性。例如,当面对涉及复杂财务数据的查询时,TableRAG能够迅速提取相关信息,并生成符合用户需求的精确回答。如果您对这一方法还不熟悉,我们建议您先回顾TableRAG的相关研究成果,以全面了解我们在数据处理优化方面的技术路径。
尽管RAG技术在多个领域表现出色,但处理非结构化文本数据仍然面临着独特的挑战。非结构化文本的数据形式更加复杂,语义关系多样且层次分明,这使得传统的RAG模型在面对复杂查询时,难以获得理想的结果。在我们的研究中,我们发现了以下四个关键问题,这些问题在非结构化文本处理过程中尤为突出:
多层次语义分割的精度问题:非结构化文本往往包含多个语义层次和复杂的逻辑结构。如果不能精确分割这些层次,系统可能会将紧密相关的信息割裂,或错误地将不相关的信息混合在一起。例如,在处理一份详细的法律文档时,系统可能会误将法律条款和解释性说明分割开,导致检索结果失去了上下文的完整性。尤其是在长篇文档中,准确识别并分割不同的语义层次对于保持信息的连贯性至关重要。
上下文生成的深度与广度问题:在处理复杂查询时,系统需要生成足够丰富和全面的上下文信息,以确保回答的深度和广度。这意味着系统不仅需要提供直接相关的信息,还需要捕捉到与查询相关的背景、前因后果及细节。如果上下文生成不够全面,系统可能会遗漏关键信息,导致回答不完整或片面。这种局限性特别明显,当用户提出需要全面背景或涉及多个主题的查询时,如果系统只提供片段式的信息,而缺乏完整的上下文,最终的回答将难以满足用户的需求,并且可能会误导用户对信息的理解。
复杂查询的语义相关性排序问题:初步检索出的内容可能包含许多与查询部分相关的段落,但这些段落的排序可能不够精准,导致用户获取的信息不够精确。例如,对于一个关于气候变化影响的复杂查询,系统可能会优先展示一些次要影响,而将主要影响放在后面,影响用户对信息的整体理解。如何在检索结果中准确排序相关内容,直接影响最终生成内容的质量和连贯性。
多文档信息整合的难度:在处理复杂查询时,系统通常会返回多个最相关的文本块来回答问题。当查询较为简单且范围较小时,如“莎士比亚的出生年份是什么?”,系统只需返回一个单一的文本块即可准确回答问题。这种方式在处理简单、直接的问题时效果良好。然而,当查询范围较为宽泛或复杂时,传统的RAG方法在整合多个块以生成完整的回答时则面临显著挑战。
例如,针对“描述过去十年中气候变化对全球经济的影响”这样的问题,系统可能需要从多个不同的文档中提取信息块。这种情况下,传统RAG方法往往难以有效整合来自不同文档的相关内容,导致返回的信息块之间缺乏连贯性,信息割裂,或者遗漏了关键的跨文档关联。
此外,对于一些问题,可能需要从同一文档的多个不同位置提取信息。例如,回答“总结某份财务报告中提到的主要风险因素及其对策”时,可能需要从文档的开头部分提取风险因素,并从结尾部分提取对策。如果块的划分过小,系统可能无法捕捉足够的上下文,导致回答缺乏语义连贯性;但如果块划分过大,大到一个块包含文档的开头和结尾,则会不可避免地包含大量无关信息,降低回答的精准度。
因此,如何在块划分和整合上进行优化,以确保信息的连贯性和相关性,是RAG技术在处理宽泛或复杂查询时面临的一个重要挑战。
为了解决这些问题,我们开发了TextRAG。通过优化RAG模型的核心能力,TextRAG在处理非结构化文本数据时表现得更加出色。TextRAG通过引入语义切片、自动上下文生成、相关片段提取和智能块整合等关键技术,增强了模型对复杂文本的理解力和生成能力。这些技术创新不仅显著提高了文本数据的检索精准度和生成质量,尤其是在处理复杂语义查询时,展现了卓越的性能。
在接下来的部分中,我们将详细探讨TextRAG的核心技术组件,展示这些创新方法如何推动非结构化文本数据处理的进步。
Overall
核心框架介绍
为了应对非结构化文本数据处理中所面临的关键挑战,我们开发了TextRAG。TextRAG的整体架构由四个主要部分组成:Context Segmentation(上下文分割)、Context Generation(上下文生成)、Rerank(重排序)和 Chunks Integration(块整合)。以下是TextRAG的总体架构流程图:
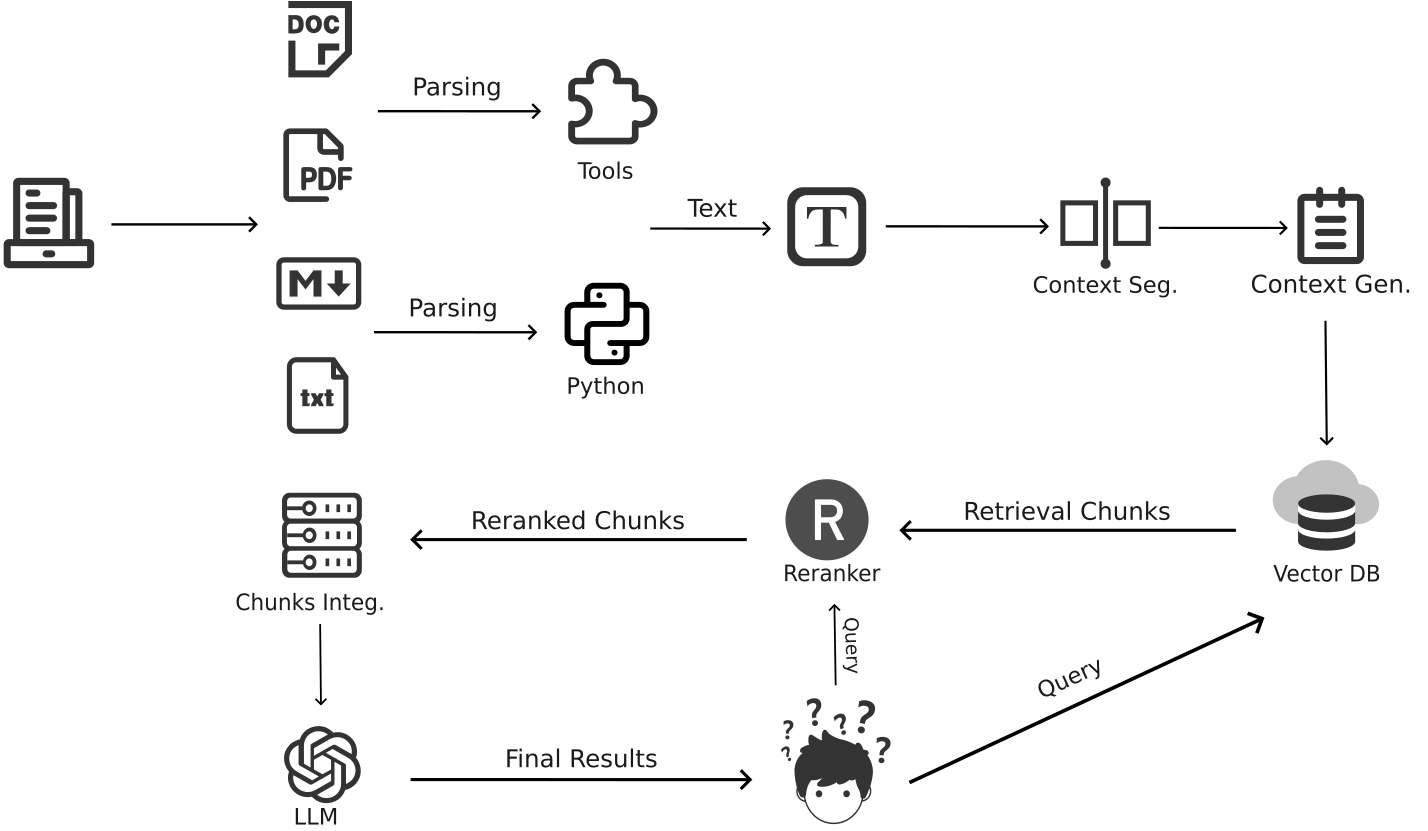
这个流程图展示了TextRAG在处理复杂文本数据时的整体设计。每个模块在应对具体问题时都发挥了至关重要的作用。
Context Segmentation(上下文分割)
Context Segmentation模块是TextRAG的基础,负责将长篇文本按照语义和上下文逻辑分割成多个部分。这一分割过程确保每个部分都是连贯且有意义的,避免了多层次语义分割中的精度问题。例如,在处理一篇复杂的学术文章时,系统通过逐行拆分并利用大语言模型(LLM)进行结构化分割,将相关内容进行精准分割。此外,系统在分割的同时还生成简洁且描述性的标题,使得用户能够通过标题快速掌握每个部分的主要内容。这不仅优化了长文档的处理效率,也提高了信息检索的精度和效率。
Context Generation(上下文生成)
在完成上下文分割后,Context Generation模块进一步丰富每个分割部分的上下文信息。它通过生成文档级和节级的标题、摘要等,确保生成的上下文信息具有足够的深度和广度。例如,在复杂查询中,生成的文档摘要能够概述整个文档的核心内容,而章节摘要则提供了更细粒度的语义背景。这一模块不仅帮助系统生成全面的回答,还解决了多文档信息冲突的问题,确保回答的连贯性和一致性。
Rerank(重排序)
在文本检索过程中,Rerank模块对初步检索到的文本块进行精细化的重排序。传统的RAG方法可能无法准确排序与查询相关的内容,导致信息片面或不连贯。通过使用更精细的语言模型(如Cohere或VoyageAI),Rerank模块能够基于语义相关性对文本块进行二次排序,确保最终返回的结果与查询的相关性最高。这一模块显著提升了复杂查询的回答质量,并优化了信息整合的逻辑顺序。
Chunks Integration(块整合)
在重排序之后,Chunks Integration模块通过智能组合相关的文本块,确保返回的查询结果不仅高相关性,而且具有连贯性和完整性。这个模块特别擅长处理多文档信息整合和跨段落信息整合的难题。对于需要从多个文档中提取信息的复杂查询,Chunks Integration模块能够智能地将不同来源的文本块整合成一个连贯的段落,避免信息割裂的问题。同样,在需要从同一文档的开头和结尾部分提取信息的情况下,该模块通过动态调整块的大小,既避免了包含过多无关信息的风险,也确保了信息的完整性和上下文的连贯性。这使得TextRAG能够在面对复杂查询时提供全面且精准的回答。
在接下来的部分中,我们将详细探讨这些核心组件的工作原理,并展示它们在非结构化文本数据处理中的应用效果。通过这些详细讲解,您将深入了解TextRAG如何在复杂的文本处理任务中提供卓越的性能和结果。
Part 1: Context Segmentation
在非结构化文本数据处理中,将文档划分为语义清晰且结构明确的部分是提升整体处理效率与效果的基础。Context Segmentation(上下文分割)通过将长篇文档分割为多个内容连贯、主题集中的部分,为后续的上下文生成(Context Generation)和块整合(Chunks Integration)提供了坚实的语义基础。
Context Segmentation的步骤详解
文档的行级别拆分与编号
为了确保文档在分割过程中的精确性,首先将文档内容按行进行拆分,并为每一行添加编号。这种处理方式使得后续的语义分析可以基于具体的行号来进行操作,从而确保了分割过程的精确性。
例如,对于以下文本片段:
1
2
3[1] Climate change is one of the most pressing issues of our time.
[2] The Earth’s temperature has risen significantly over the past century.
[3] Scientists attribute this rise to the increased concentration of greenhouse gases.在处理过程中,将其分割为三行,并分别编号为[0]、[1]、[2]。这种编号方式不仅便于后续的分割和处理,也为语义分析提供了准确的定位基础。
基于大语言模型(LLM)的结构化分割
在文档被逐行拆分并编号后,使用大语言模型(LLM)对文档进行结构化分割。LLM基于文档内容的实际语义和逻辑结构,将其分割为若干部分,每个部分都围绕一个特定的主题或概念展开。
在这个过程中,LLM不仅分析文本的语义,还结合行号信息,生成每个部分的起始和结束位置。这一结构化分割的过程依赖于特定的提示(prompt)设计,确保分割结果与文档的自然逻辑高度一致。具体的说,我们使用的prompt如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28system_prompt = """
**Task: Structured Document Creation**
You are provided with a document that includes line numbers. Your task is to create a StructuredDocument object by dividing the document into several sections. Each section should focus on a specific topic or concept. Please follow the instructions below carefully:
**Document Division:**
- Divide the document into several sections based on its content. Each section should discuss a single topic or concept.
- The sections should align as closely as possible with the document's natural divisions, such as "Introduction," "Background," "Discussion," "Conclusion," etc.
**Line Number Annotation:**
- For each section, note the starting and ending line numbers.
- The start_index should be the line number of the first line in that section, and the end_index should be the line number of the last line in that section. For example, if a section begins at line 5 and ends at line 10, the start_index should be 5, and the end_index should be 10.
**Complete Coverage of the Document:**
- Ensure that all sections together cover the entire document without any gaps or overlaps.
- The first section should begin at the document's first line, and the last section should end at the document's last line. No lines should be left out, and no sections should overlap.
**Section Titles:**
- Create a concise and descriptive title for each section, allowing the reader to grasp the main content of the section just by reading the title.
**Judgment and Flexibility:**
- Note that this document might be an excerpt from a larger document. Therefore, do not assume that the first line is necessarily an "Introduction" or the last line is a "Conclusion."
- You must make a reasonable division based on the actual content and assign an appropriate title to each section.
The final goal is to produce a StructuredDocument where each section focuses on a specific topic, with accurately marked line number ranges, to clearly and comprehensively reflect the document's content structure.
"""迭代处理长篇文档
对于较长的文档,通常无法在一次处理过程中完成全部分割,因此采用迭代处理的方法。通过多次调用LLM,每次处理文档的一部分,逐步完成整个文档的分割。这种方法保证了即使在处理超长文档时,系统也能有效地对其进行语义分割,确保每个部分的完整性和连贯性。
验证和修正分割结果
在完成所有分割操作后,必须对分割结果进行验证,以确保其无缝覆盖了文档的全部内容。任何重叠、遗漏或不连续的部分都会通过修正过程被调整,以生成最终的、结构化的文档分割。这一步骤确保了分割结果的准确性和可靠性,为后续处理奠定了坚实的基础。
Example
Document Content:
1 | [1] Climate change is one of the most pressing issues of our time. |
Structured Document Example:
1 | { |
总的来说,Context Segmentation在非结构化文本数据处理中具有不可替代的作用。通过将文档内容合理划分为多个语义明确的部分,Context Segmentation不仅为后续的上下文生成和段落整合提供了必要的语义框架,还显著提升了文本处理的精度与效率。通过这种结构化的分割方法,系统能够更加准确地理解文本的内在逻辑,进而提高信息检索和生成的效果。
Part 2: Context Generation
在非结构化文本数据处理中,除了对文档进行有效的语义分割外,还需要为每个文本片段生成精确的上下文信息,以支持系统的深层语义理解和高效信息检索。Context Generation(上下文生成)通过为文档的各个部分生成标题、摘要以及上下文块,帮助系统更好地捕捉文本的核心内容和语义关联,为后续的嵌入和检索过程提供坚实的语义基础。
Context Generation的步骤详解
文档标题生成
在处理非结构化文本时,生成一个精准且简洁的文档标题是至关重要的。文档标题不仅能够快速传达文档的主题,还为后续的上下文生成和段落整合提供了语义锚点。系统首先会根据文档内容生成一个标题,该过程依赖于大语言模型(LLM)对文本内容的分析。
我们使用以下提示词(prompt)来生成文档标题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16DOCUMENT_TITLE_PROMPT = """
INSTRUCTIONS
Please provide the title of the document based on the content provided below.
IMPORTANT:
- Your response must ONLY be the title of the document.
- Do NOT include any additional text, explanations, or comments.
{document_title_guidance}
{truncation_message}
DOCUMENT CONTENT:
{document_text}
""".strip()在生成文档标题时,系统会首先截取文档的前几千个词语,并将这些内容传递给LLM。LLM根据提供的文本内容生成一个能够概括文档主要主题的标题。生成的标题必须简洁明确,并能准确反映文档的核心内容。
文档摘要生成
文档摘要是信息检索和文本生成任务中的重要组成部分。通过生成文档摘要,系统能够快速获取文档的核心内容,从而提升检索的精准度。文档摘要的生成同样依赖于LLM的语义分析。
生成文档摘要的提示词如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23DOCUMENT_SUMMARIZATION_PROMPT = """
INSTRUCTIONS
Please summarize the content of the document in a single, concise sentence.
IMPORTANT:
- Your summary should begin with: "This document is about: "
- The sentence should be clear and to the point, covering the main topic of the document.
- Do NOT add any additional information or context beyond the main topic.
Example Summaries:
- For a history book titled "A People's History of the United States," you might say: "This document is about: the history of the United States, covering the period from 1776 to the present day."
- For the 2023 Form 10-K of Apple Inc., you might say: "This document is about: the financial performance and operations of Apple Inc. during the fiscal year 2023."
{document_summarization_guidance}
{truncation_message}
DOCUMENT TITLE: {document_title}
DOCUMENT CONTENT:
{document_text}
""".strip()系统通过特定的提示词,引导LLM生成一个简洁的文档摘要,通常为一句话,直接指出文档的主要内容或主题。文档摘要不仅为系统提供了全局性的语义背景,也为后续的上下文生成提供了必要的支持。
章节摘要生成
对于被分割为多个部分的长篇文档,生成每个部分的摘要尤为重要。章节摘要能够帮助系统在更细粒度上理解文本的语义结构,从而在检索和生成任务中提高准确性。(章节标题在Part 1划分时已经生成)
我们使用的章节摘要生成提示词如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23SECTION_SUMMARIZATION_PROMPT = """
INSTRUCTIONS
Please summarize the content of the following section in a single, concise sentence.
IMPORTANT:
- Your summary should begin with: "This section is about: "
- The sentence should clearly describe the main topic or purpose of this section.
- Do NOT add any additional information or context beyond the main topic of the section.
Example Summary:
- For a balance sheet section of a financial report on Apple, you might say: "This section is about: the financial position of Apple as of the end of the fiscal year."
- For a chapter on the Civil War in a history book, you might say: "This section is about: the causes and consequences of the American Civil War."
{section_summarization_guidance}
SECTION TITLE: {section_title}
DOCUMENT TITLE: {document_title}
SECTION CONTENT:
{section_text}
""".strip()通过这一提示词,系统能够生成每个章节的简要摘要,清晰指明该章节的主要内容和目的。这种细粒度的语义理解对于处理长篇复杂文档尤为重要。
Flowchart
开发过程中所构建的流程图如下:

Example
Document Content:
The document is an extensive report on the various effects of climate change on polar bear populations in the Arctic. The report is divided into several sections:
- Introduction: This section provides an overview of the current status of polar bears and the key challenges they face due to climate change. It introduces the main themes of the report, such as habitat loss, changing prey availability, and the impact of human activities.
- Melting Sea Ice: This section discusses the drastic reduction in sea ice in the Arctic, which serves as a critical habitat for polar bears. It explains how the loss of sea ice has affected polar bear hunting behaviors, forced them to migrate longer distances, and led to a decline in their overall population.
- Impact on Prey Availability: This section examines how climate change has disrupted the availability of prey for polar bears, particularly seals. It discusses the cascading effects on the polar bear food chain and how changes in prey distribution are leading to malnutrition and decreased reproductive rates among polar bears.
- Human Activities and Pollution: This section explores how human activities, including oil drilling, shipping, and pollution, are further exacerbating the challenges faced by polar bears. It discusses the potential long-term effects of pollutants on polar bear health and how industrial activities are encroaching on their habitats.
- Conservation Efforts and Future Strategies: This section reviews current conservation efforts aimed at protecting polar bears and their habitats. It also proposes future strategies that could mitigate the impact of climate change, such as reducing greenhouse gas emissions, protecting critical habitats, and developing new conservation policies.
- Conclusion: The conclusion summarizes the key findings of the report and emphasizes the urgent need for coordinated global efforts to protect polar bears in the face of ongoing climate change.
Context Generation
1 | # Step 1: Document Title Generation |
总的来说,通过生成文档标题、文档摘要、章节摘要,以及上下文块和段落头部,系统能够在多个层次上理解文本的语义结构,并为每个文本块提供必要的上下文信息。这一过程不仅提升了系统在信息检索和文本生成任务中的表现,还为整个系统的语义处理奠定了坚实的基础。
在后续的部分中,将进一步探讨Chunks Integration的技术细节,分析这些技术如何在复杂文本处理任务中发挥作用。通过这些分析,可以更全面地理解textrag如何通过上下文生成来优化文本处理的效果,并实现高效的语义理解与信息整合。
Part 3: Reranking
在非结构化文本数据处理中,初步的搜索结果通常基于嵌入向量的相似性,筛选出与查询相关的文本块(chunks)。然而,这种基于向量的初步排序可能无法充分捕捉查询的深层语义,导致某些文本块尽管表面上相关,但在实际语义上可能与用户的查询存在偏差。为了进一步提升检索结果的准确性和相关性,Reranking(重新排序)步骤成为必不可少的环节。
Reranking Details
在文本块检索的初步阶段,textRAG通过嵌入向量的相似度,从数据库中筛选出最相关的前top-k个chunks。这些初步筛选出的chunks反映了与查询的初步相似性,但在处理复杂语义时可能存在局限,尤其是在面对高度语义复杂性的文本时。为了解决这些问题,Reranking步骤通过更为精细的语言模型(如Cohere或VoyageAI),对初步筛选出的文本块进行二次分析和重新排序,从而更好地捕捉文本块与查询之间的语义关联。
在Reranking过程中,textRAG首先利用高级语言模型对这些top-k个文本块与查询进行更深入的评估。每个文本块会被重新分配一个新的相关性得分,并根据新的得分重新排序。这些得分随后会经过特定的变换处理,使其均匀分布在0到1之间。这一变换通过贝塔分布函数实现,确保得分分布的均衡性和敏感性,使得textRAG能够更精准地区分出文本块之间的细微差异。重新排序后的文本块,尽管是同一批初始筛选出的chunks,但它们的顺序、得分和排名都经过了重新调整,以更好地反映其与查询的实际语义相关性。
Why transform the score?
将相关性得分变换为0到1之间的均匀分布,是Reranking过程中的一个关键步骤。这种变换通过贝塔分布函数实现,旨在避免得分分布过于极端,从而提升Reranking结果的可靠性。得分的这种均匀分布,确保了在后续的Chunks Integration(块整合)过程中,各个文本块的相关性得分能够被合理且有效地综合考虑。
具体而言,在块整合过程中,textRAG需要将多个经过Reranking的文本块整合成连贯的片段组合。得分的均匀分布确保了这些文本块在整合时,能够根据其实际的语义相关性进行更精准的排序和选择。这样,textRAG在段落整合时,可以更有效地排列和组合文本块,形成语义连贯、信息密集的段落,进一步提升系统的整体表现。
Reranking不仅是提升文本检索精度的重要步骤,还为后续的块整合奠定了坚实的基础。通过将相关性得分转化为0到1之间的分布,textRAG确保了每个文本块的得分更具区分性,从而在块整合时能够更加精确地排列和选择文本块。这一过程大大增强了系统在处理复杂查询时的能力,确保最终生成的内容既连贯又高度相关。
在接下来的Chunks Integration部分,我们将详细探讨如何利用这些经过Reranking的文本块,整合出更为连贯和语义丰富的片段组合,并通过上下文信息的进一步补充,提升textRAG在生成文本和信息检索中的整体表现。
Part 4: Chunks Integration
在非结构化文本数据处理过程中,textRAG通过对文档进行块(chunk)划分,将其分解为较小的文本单元,以便更精细地进行信息检索和分析。然而,块的划分本身存在一定的挑战:如果块划分得过小,文本的上下文可能被切断,导致语义信息丢失;而如果块划分得过大,则会包含过多无关信息,影响检索的精准度。尤其在处理一些复杂、宽泛的问题时,单个块往往不足以提供完整的答案,这就引出了Chunks Integration(块整合)这一关键步骤,它旨在通过整合多个文本块,确保系统返回的结果既完整又准确。
Why Chunks Integration?
在文本检索中,块的划分直接影响到最终结果的质量。块划分过小和过大的情况各有其缺点:
- 块划分过小的缺点:
- 语义割裂:当文本被切分得过于细小时,原本连贯的上下文会被打断。比如在讨论复杂的理论或历史事件时,关键信息可能分散在多个块中,单一块无法提供完整的背景和逻辑。
- 信息不完整:过小的块可能只包含部分相关信息,而无法给出完整的答案。这会导致用户需要多个块才能理解整个内容,增加了查询结果的复杂性。
- 检索效率低:因为信息被分散在多个小块中,系统在处理和整合这些块时需要花费更多的计算资源和时间,从而降低了检索的效率。
- 块划分过大的缺点:
- 噪声增加:较大的块往往包含大量无关信息,这些信息可能干扰核心内容的呈现,降低检索结果的精准度。
- 难以精确匹配:当块过大时,系统在进行匹配时难以找到与查询完全匹配的内容,可能返回包含大量无关内容的块,导致结果不够精确。
- 信息冗余:过大的块可能重复包含与查询无关的内容,导致结果显得冗长且难以提炼出关键信息,影响用户体验。
这些问题在处理复杂查询时尤为突出。例如,对于“莎士比亚的出生年份是什么?”这样的简单查询,一个文本块即可准确回答,因为信息集中且明确。然而,对于某些复杂且宽泛的问题,单个文本块可能无法提供全面的答案。
举例来说,考虑一个问题:“《哈姆雷特》中描述悲剧性命运的段落有哪些?”这个问题需要跨越整部戏剧,提取出散布在不同场景中的多个段落。如果块划分过小,回答会被分割成多个不连贯的部分;如果块划分过大,回答可能包含太多无关的剧情描述,使得答案失去焦点。
再如,考虑一个历史性问题:“第二次世界大战期间,导致珍珠港事件爆发的主要因素是什么?”这类查询涉及复杂的历史背景,答案可能需要从文献中的不同部分获取信息。例如,事件的前因可能位于文档的开头,而后果和总结可能出现在结尾部分。在这种情况下,仅依赖单一文本块无法提供完整的视角,导致答案片面或不准确。
正因为如此,Chunks Integration的必要性便显得尤为重要。对于复杂查询,仅返回一两个块不仅可能无法全面回答问题,还可能导致回答的不准确或片面。通过将相关的块进行整合,textRAG能够生成一个语义连贯且信息全面的段落,确保复杂查询的答案既完整又精准。这种整合过程确保了系统在面对复杂查询时,能够综合多个相关文本块,提供一个详尽且有条理的回答,从而提升信息检索的质量和用户的满意度。
Implementation Details
Chunks Integration是textRAG系统中至关重要的步骤,通过优化算法将多个相关的文本块整合为语义连贯且信息全面的段落。以下是详细的实现步骤及总体架构图:
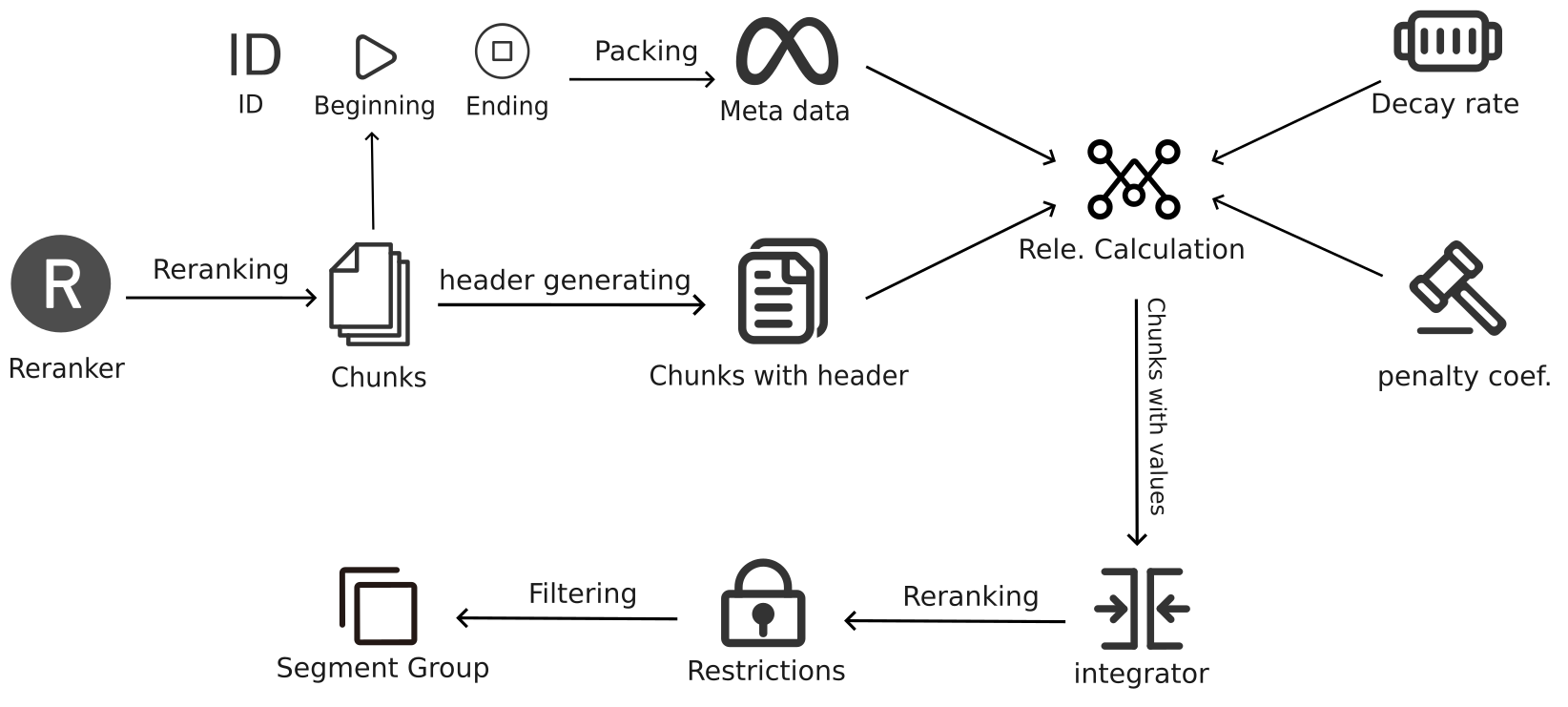
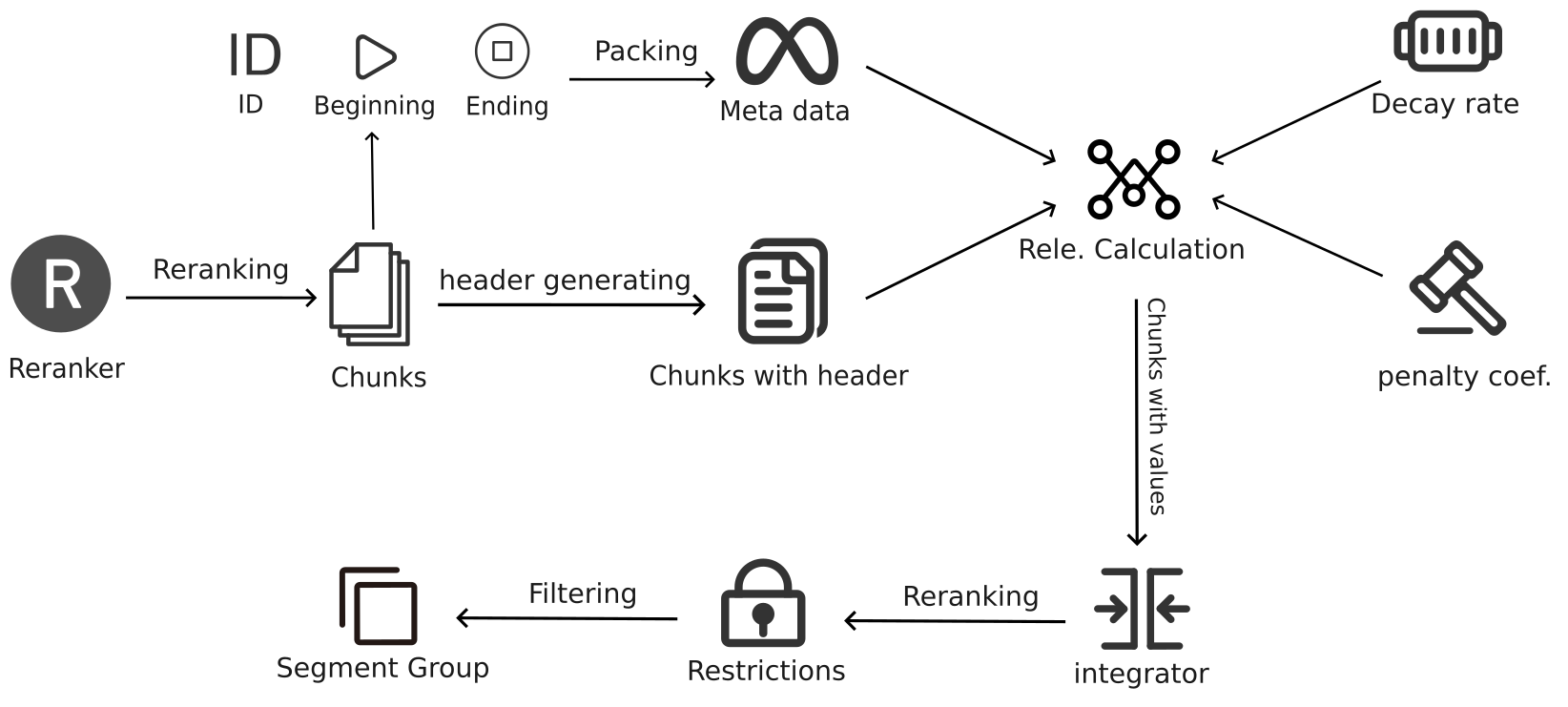
1. 构建元文档(Meta-document)
在Chunks Integration的第一步中,系统会从经过Reranking后的结果中提取每个文本块的开始点、结束点以及它们的块ID(chunk ID),并将这些信息构成一个元文档。这个元文档并不包含具体的文本内容,而是一个索引结构,记录了各个相关文本块在文档中的位置。这一索引结构为后续的段落整合提供了基础,确保系统在处理过程中能够准确识别和组合相关的文本块。
通过这种方式,系统建立了一个包含所有相关文本块的元文档,明确了每个文本块在整个文档中的位置及其相对关系,从而为后续的段落整合奠定了坚实的基础。
2. 评估文本块的相关性
构建好元文档后,系统需要评估每个文本块的相关性值(relevance value)。这一步骤接收多个输入参数,包括元文档中的所有参数、重排序后的结果、不相关惩罚系数(irrelevant chunk penalty)以及衰减率(decay rate)。这些参数共同作用,决定了文本块与查询的匹配度。接下来将详细描述这个过程。
- 输入参数:
- 元文档参数:包括每个文本块的开始点、结束点以及块ID。
- 重排序后的结果:这些结果包含每个文本块的排名(rank)和绝对相关性值(absolute relevance value)。
- 不相关惩罚系数(irrelevant chunk penalty):用于控制整合过程中产生的段落长度。惩罚系数越大,生成的段落越短。
- 衰减率(decay rate):决定了排名对于相关性值的影响程度。
- 相关性分数计算:
在计算文本块的相关性分数时,系统使用了get_chunk_value函数。具体步骤如下:首先,从
chunk_info中获取rank(排名)和absolute_relevance_value(绝对相关性值)。如果这些值不存在,默认rank设为1000,absolute_relevance_value设为0.0。然后计算文本块的得分
v,公式为:

rank越高(数值越大):

的值就越小,意味着得分会降低;
- absolute_relevance_value越大,文本块的初始得分就越高;
- 最后减去一个irrelevant_chunk_penalty,作为惩罚项。
不同的惩罚系数会影响生成段落的长度:
- **0.05**:生成较长的段落,通常包含20-50个块。
- **0.1**:生成10-20个块的长段落。
- **0.2**:生成4-10个块的中等长度段落。
- **0.3**:生成2-6个块的短段落。
- **0.4**:生成1-3个块的非常短的段落。
通过这种方式,系统能够动态调整段落的长度和相关性,确保生成的段落既包含足够的信息量,又不会过度冗长。
长度调整:
在计算出初步的相关性值后,系统还会根据每个文本块的长度对其得分进行进一步调整,这一步骤通过adjust_relevance_values_for_chunk_length函数实现。其具体步骤如下:输入参数:
relevance_values:get_chunk_value函数计算得到的初始相关性值列表。chunk_lengths:对应每个文本块的长度列表(以字符数为单位)。reference_length:参考长度(默认700字符),用于标准化不同长度的文本块。
计算过程:
系统遍历relevance_values和chunk_lengths,并对每个文本块的得分进行调整。具体公式为:

如果一个文本块的长度大于
reference_length,其得分会被放大;如果文本块的长度小于
reference_length,其得分会被缩小。
这一调整确保了长的文本块在整合过程中能够获得更高的得分,而短的文本块得分较低,从而在整合过程中平衡不同长度的文本块的影响。
这些调整过程的作用在于,通过考虑文本块的长度和相关性,系统能够更加准确地评估每个文本块的价值,从而在后续的段落整合过程中选择出最有价值的文本块组合。这种方法确保了最终生成的段落在信息密度和语义连贯性方面达到最佳效果。
3. 选择最优片段组合:优化算法的应用
在评估完所有chunks的相关性分数后,textRAG系统会应用优化算法,生成多个最优的片段组合(Segment Grouping)。这一过程非常关键,它决定了最终返回给用户的内容是否能够准确、完整地回答复杂的查询。为此,系统会基于多种约束条件,进行精确的组合优化。以下是详细的步骤:
传入参数
优化算法的输入包括在前一步中计算得到的相关性分数以及多个关键的约束条件。这些参数决定了哪些chunks会被选择,以及它们如何被组合成片段组合:
- 相关性分数:这是由前面的步骤计算出的分数,反映了每个chunk与查询的匹配度,是优化算法选择chunks的核心依据。在这个步骤之前,每个chunk已经通过
get_chunk_header函数添加了上下文信息,这些信息包括文档标题、文档摘要、章节标题和章节摘要,确保在计算和选择过程中,chunks具备完整的语义背景。 - 约束条件:
- 最大组合长度(max_length):规定了单个片段组合中最多可以包含的chunks数量。这一条件防止生成的片段组合过长,确保信息集中且连贯。
- 整体最大长度(overall_max_length):限制了所有片段组合的总长度,防止返回的内容过于冗长。
- 最小相关性阈值(minimum_value):确保只有达到或超过这一分数的chunks才会被考虑整合,从而排除不相关或低相关性的内容。
优化组合chunks
在接收到相关性分数和约束条件后,系统开始优化组合chunks,生成一个或多个片段组合(Segment Grouping):
- 遍历相关性分数:系统会遍历所有查询的相关性分数,寻找得分最高的chunks,并将它们组合在一起。这些chunks的组合形成了一个片段组合,能够共同提供查询所需的信息。
- 检查约束条件:在生成片段组合时,系统会严格遵守以下约束条件:
- 最大chunks限制:每个片段组合中的chunks数量不能超过
max_length。如果某个组合超出这一限制,系统将停止向该组合中添加chunks,并开始创建一个新的片段组合。 - 文档来源限制:为了保持片段组合的语义连贯性,每个组合中的所有chunks必须来自同一个文档。如果当前的chunk与已选chunks来自不同的文档,系统会开始创建一个新的片段组合。
- 整体长度限制:系统会累积所有生成的片段组合的chunks总数,确保其不超过
overall_max_length。一旦达到这一限制,系统将停止创建新的片段组合,即使还有相关的chunks未被选入。
- 最大chunks限制:每个片段组合中的chunks数量不能超过
- 生成多个片段组合:系统可能会生成多个片段组合,每个组合内部的chunks都是紧密相关且语义连贯的,这些组合将共同提供对查询的完整回答。在这一过程中,生成的片段组合还会使用
get_segment_header函数添加上下文信息,如文档标题和文档摘要,以便在后续处理中提供完整的语义背景。
参数选择与调整
参数的选择对片段组合的生成有重要影响,不同的应用场景需要不同的参数设置:
- 最大组合长度(max_length):如果查询需要更广泛的上下文,可以选择较大的
max_length,以包含更多的chunks;而对于需要精确回答的查询,则较小的max_length更为合适。 - 整体最大长度(overall_max_length):这一参数通常根据用户期望的响应长度来设定。对于简短的答案,
overall_max_length应设定较小;对于需要详细回答的查询,则可以选择较大的值。 - 最小相关性阈值(minimum_value):通常设定在一个较高的水平,以排除噪音内容。然而,对于需要更广泛信息的查询,可以适当降低这一值,以纳入更多内容。
这些参数的选择通常通过实验与调整来确定,以达到最佳的平衡。例如,在处理需要整合大量信息的复杂查询时,可以适当提高max_length和overall_max_length,并降低minimum_value以包含更多的chunks。而对于需要精确、简洁回答的查询,则反之调整。
Segment Grouping
在完成所有可能的组合计算后,系统会返回得分最高的一个或多个片段组合(Segment Grouping)。这些组合中的chunks既满足了所有的约束条件,也能够最大化相关信息的整合,确保内容既连贯又完整。
通过这种优化算法,textRAG系统能够针对复杂查询生成语义连贯、信息密集的片段组合。这一过程解决了简单chunk检索可能导致的信息碎片化和语义割裂问题,确保最终生成的内容能够为用户提供全面、准确的回答,为textRAG系统在复杂信息检索任务中的出色表现提供了强有力的支持。
Flowchart
开发过程中该模块的流程图如下:

Evaluation
本节旨在详细介绍textrag系统的评估实验过程。我们选择了FINANCEBENCH数据集作为主要评估基准,通过严谨的实验设计验证textrag在处理复杂金融信息查询中的性能。
FINANCEBENCH
FINANCEBENCH是一个专门用于评估语言模型在金融领域问答任务中的表现的基准数据集。该数据集涵盖了10,231个与上市公司相关的问题,内容广泛,涵盖了以下三个主要类别:
- 领域相关问题:这些问题主要涉及公司财务分析中的基本指标,如营收、净利润等,测试模型在处理标准财务数据方面的能力。
- 新生成问题:这些问题设计得更为复杂,旨在考验模型的语义理解和推理能力,特别是在处理多层次信息时的表现。
- 指标生成问题:这些问题需要模型进行财务指标的计算与推理,测试其综合分析能力。
该基准旨在通过具有挑战性的财务问答任务,评估语言模型在信息检索、语义理解和推理方面的能力,从而为模型在金融领域的应用设立最低性能标准。
textrag的评估实验设计
为了验证textrag在处理复杂金融信息查询中的有效性,我们设计了一系列实验,这些实验包括从知识库构建到最终答案生成的全过程。
- 知识库构建
- 文档收集与预处理:我们从上市公司的财务报告中收集了大量文档(如10-K和10-Q),这些文档经过预处理后被逐行拆分为多个chunks,并嵌入到知识库中。
- 知识库生成:通过Cohere嵌入模型,我们将处理后的文档片段转化为知识库中的可查询数据。知识库的构建在一个共享向量存储(Shared Vector Store)的配置下进行,这意味着多个查询可以同时高效地访问相同的向量数据,极大地提升了检索效率和系统的可扩展性。
- 自动生成查询
- 查询生成:针对每个问题,利用大语言模型(如Claude 3)自动生成最多6个具体的搜索查询。这些查询设计得足够精准,以便能够定位到文档中最相关的信息片段。
- 查询优化:生成的查询经过进一步优化,以确保其高效性和相关性,使得系统能够检索到最为准确的内容。
- 检索与响应生成
- 上下文检索:系统在知识库中执行生成的查询,提取与问题相关的文本片段,并将这些片段整合成完整的上下文。通过多层次的检索和整合,系统能够为复杂问题生成所需的背景信息。
- 生成最终响应:利用GPT-4-Turbo模型,在获取的上下文基础上生成最终的回答。生成过程注重答案的简洁性和准确性,确保能够充分回应用户的查询。
- 实验结果与分析
- 结果对比:将系统生成的答案与FINANCEBENCH提供的标准答案进行对比,计算模型的准确率和召回率。实验结果表明,在Shared Vector Store配置下,textrag的回答准确率达到79%,显著高于基准模型19%的准确率。
- 手动评估:对部分复杂查询进行人工评审,以进一步验证系统在多文档检索和信息整合中的表现。
- 性能指标评估:通过计算精度、召回率等指标,量化textrag在处理金融问答任务中的性能,并与基准模型进行全面对比。
实验总结与未来工作
本次评估实验表明,textrag在Shared Vector Store配置下,在复杂的金融问答任务中表现出色。其回答准确率达到79%,相比基准模型的19%有了显著提升。这一结果证明了textrag在处理复杂语义查询和多文档整合方面的优势,尤其是在金融领域的实际应用中,具有重要的价值和潜力。
未来,我们计划对系统的召回率、精度等性能指标进行更为精准的评估,以进一步优化textrag的性能表现。通过这些后续研究,textrag将能够更好地应对多样化的查询需求,提供更为全面和可靠的答案。
(To be continued…)
Reference
[A long waiting lists …]