© Wuyuhang, 2024. All rights reserved. This article is entirely the work of Wuyuhang from the University of Manchester. It may not be reproduced, distributed, or used without explicit permission from the author. For inquiries, please contact me at yuhang.wu-4 [at] postgrad.manchester.ac.uk.
Background
In the current digital era, the amount of unstructured data is growing at an astonishing rate, becoming the primary form of information storage and transmission. Research indicates that over 80% of global data exists in unstructured formats, the vast majority of which is textual data. This data is ubiquitous across various industries, from legal documents and academic papers to corporate financial reports and social media content. However, despite the vast potential for information retrieval and knowledge discovery that this unstructured text data offers, effectively processing and utilizing it remains a challenge that has yet to be fully addressed.
Retrieval-Augmented Generation (RAG) technology combines the strengths of retrieval systems and large language models (LLMs), enabling the generation of content with reference to external knowledge bases, thereby significantly enhancing the accuracy and relevance of the generated content. RAG technology is particularly effective in handling complex queries that require extensive background information, as it can quickly retrieve relevant information from large datasets and generate high-quality content through LLMs. This method has been widely adopted across various fields, especially in scenarios requiring real-time generation of highly accurate responses.
We have previously made significant progress in processing structured tabular data, particularly through the TableRAG method, which successfully optimized the process of retrieving and generating information from structured tables. TableRAG enhances the RAG model, improving the efficiency and accuracy of extracting information from tabular data. For instance, when dealing with queries involving complex financial data, TableRAG can quickly extract relevant information and generate precise responses tailored to user needs. If you are not yet familiar with this method, we recommend reviewing the relevant research on TableRAG to gain a comprehensive understanding of our technical approach to optimizing data processing.
Despite RAG technology’s strong performance across various domains, processing unstructured text data presents unique challenges. Unstructured text data is more complex in form, with diverse and layered semantic relationships, making it difficult for traditional RAG models to achieve optimal results when faced with complex queries. In our research, we have identified the following four key issues that are particularly prominent in the process of handling unstructured text:
Accuracy of Multi-level Semantic Segmentation: Unstructured text often contains multiple semantic levels and complex logical structures. If these levels are not accurately segmented, the system may either separate closely related information or incorrectly mix unrelated information. For example, when processing a detailed legal document, the system might erroneously segment legal clauses from explanatory notes, resulting in retrieval outputs that lose contextual integrity. Accurately identifying and segmenting different semantic levels is crucial for maintaining information coherence, especially in lengthy documents.
Depth and Breadth of Context Generation: When handling complex queries, the system needs to generate sufficiently rich and comprehensive contextual information to ensure the depth and breadth of the responses. This means the system must provide not only directly relevant information but also capture background, causes, effects, and details related to the query. If the context generation is not comprehensive, the system might miss critical information, leading to incomplete or biased responses. This limitation is particularly evident when users pose queries that require extensive background or involve multiple topics. If the system only provides fragmented information without a complete context, the final response may fail to meet user needs and potentially mislead the user’s understanding.
Semantic Relevance Ranking for Complex Queries: Initial retrieval may yield many paragraphs partially relevant to the query, but their ranking might not be precise enough, leading to suboptimal information retrieval. For instance, in a complex query about the impacts of climate change, the system might prioritize minor effects over major ones, affecting the user’s overall understanding of the information. How relevant content is ranked in the retrieval results directly impacts the quality and coherence of the final generated content.
Challenges in Multi-document Information Integration: When dealing with complex queries, the system typically returns multiple relevant text blocks to answer the question. For simple and narrowly scoped queries, such as “What is Shakespeare’s birth year?”, the system needs to return only a single text block to provide an accurate answer. This method works well for simple, direct questions. However, when the query is broader or more complex, traditional RAG methods face significant challenges in integrating multiple blocks to generate a complete response.
For instance, in response to a query like “Describe the impact of climate change on the global economy over the past decade,” the system may need to extract information blocks from multiple documents. In such cases, traditional RAG methods often struggle to effectively integrate related content from different documents, resulting in fragmented information, lack of coherence, or missing critical cross-document links.
Additionally, some questions may require extracting information from multiple different sections of the same document. For example, to answer “Summarize the main risk factors mentioned in a financial report and their countermeasures,” information may need to be extracted from the beginning of the document for risk factors and from the end for countermeasures. If the blocks are too small, the system may fail to capture enough context, leading to a lack of semantic coherence in the response; but if the blocks are too large, encompassing both the beginning and the end of the document, they may inevitably include a large amount of irrelevant information, reducing the accuracy of the response.
Therefore, optimizing block segmentation and integration to ensure information coherence and relevance is a significant challenge that RAG technology faces when dealing with broad or complex queries.
To address these issues, we developed TextRAG. By enhancing the core capabilities of the RAG model, TextRAG excels at handling unstructured text data. TextRAG introduces key technologies such as semantic slicing, automated context generation, relevant fragment extraction, and intelligent block integration, thereby enhancing the model’s ability to understand and generate responses from complex texts. These innovations significantly improve the accuracy and quality of information retrieval and generation, particularly when dealing with complex semantic queries, where TextRAG demonstrates exceptional performance.
In the following sections, we will delve into the core technological components of TextRAG and illustrate how these innovative methods drive advancements in unstructured text data processing.
Overall
Introduction to the Core Framework
To address the critical challenges faced in processing unstructured text data, we developed TextRAG. The overall architecture of TextRAG consists of four main components: Context Segmentation, Context Generation, Rerank, and Chunks Integration. Below is a flowchart illustrating the overall architecture of TextRAG:
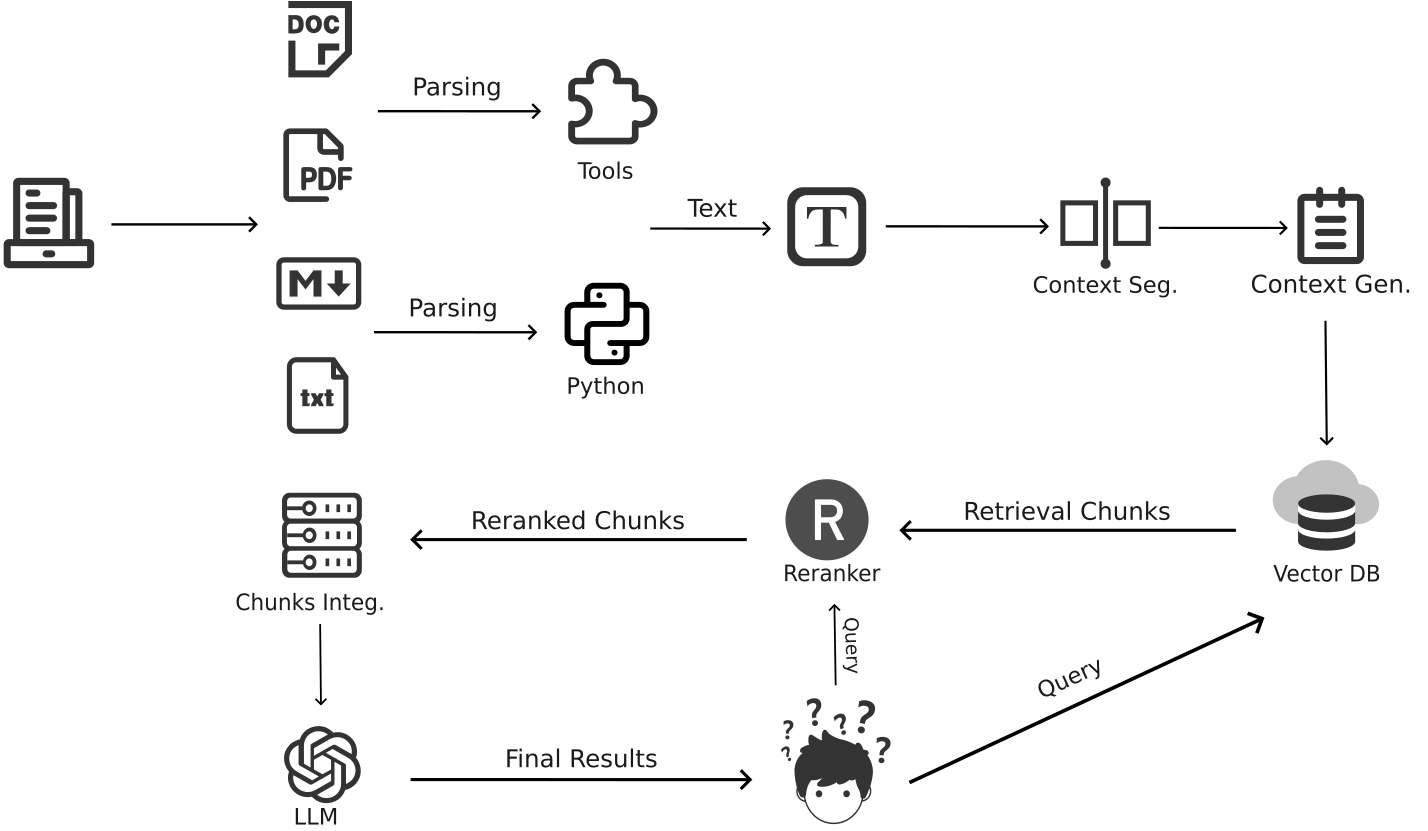
This flowchart demonstrates the overall design of TextRAG when processing complex text data. Each module plays a crucial role in addressing specific issues.
Context Segmentation
The Context Segmentation module forms the foundation of TextRAG, responsible for segmenting lengthy texts into multiple sections based on semantic and contextual logic. This segmentation process ensures that each section is coherent and meaningful, avoiding the accuracy issues associated with multi-level semantic segmentation. For example, when processing a complex academic article, the system splits the content line by line and uses large language models (LLMs) for structured segmentation, precisely dividing related content. Additionally, the system generates concise and descriptive titles during segmentation, allowing users to quickly grasp the main content of each section through the titles. This not only optimizes the processing efficiency of long documents but also improves the precision and efficiency of information retrieval.
Context Generation
After completing context segmentation, the Context Generation module further enriches the contextual information of each segmented part. It generates document-level and section-level titles, summaries, and other contextual information, ensuring sufficient depth and breadth in the generated context. For example, in complex queries, the generated document summary can provide an overview of the core content, while section summaries offer finer-grained semantic background. This module not only helps the system generate comprehensive answers but also resolves conflicts in information from multiple documents, ensuring coherence and consistency in the responses.
Rerank
During the text retrieval process, the Rerank module fine-tunes the ranking of initially retrieved text blocks. Traditional RAG methods may not accurately rank content relevant to the query, resulting in fragmented or incoherent information. By using more advanced language models (such as Cohere or VoyageAI), the Rerank module performs a secondary ranking of text blocks based on semantic relevance, ensuring that the final results returned are the most relevant to the query. This module significantly improves the quality of responses to complex queries and optimizes the logical order of information integration.
Chunks Integration
After reranking, the Chunks Integration module intelligently combines relevant text blocks, ensuring that the returned query results are not only highly relevant but also coherent and complete. This module is particularly adept at addressing the challenges of multi-document information integration and cross-paragraph information integration. For complex queries that require extracting information from multiple documents, the Chunks Integration module intelligently integrates text blocks from different sources into a cohesive paragraph, avoiding the problem of fragmented information. Similarly, when information needs to be extracted from both the beginning and end of the same document, this module dynamically adjusts the size of the blocks to avoid the risk of including too much irrelevant information while ensuring completeness and contextual coherence. This allows TextRAG to provide comprehensive and accurate responses to complex queries.
In the following sections, we will explore the working principles of these core components in detail and demonstrate their application in unstructured text data processing. Through these detailed explanations, you will gain a deeper understanding of how TextRAG delivers exceptional performance and results in complex text processing tasks.
Part 1: Context Segmentation
In processing unstructured text data, dividing documents into semantically clear and structurally defined parts is the foundation for improving overall processing efficiency and effectiveness. Context Segmentation achieves this by dividing long documents into multiple coherent, topic-focused sections, providing a solid semantic foundation for subsequent context generation (Context Generation) and chunks integration (Chunks Integration).
Detailed Steps of Context Segmentation
Line-Level Splitting and Numbering of Documents
To ensure precision during the segmentation process, documents are first split by lines, with each line numbered. This approach allows semantic analysis to operate based on specific line numbers, ensuring the accuracy of the segmentation process.
For example, consider the following text fragment:
1
2
3[1] Climate change is one of the most pressing issues of our time.
[2] The Earth’s temperature has risen significantly over the past century.
[3] Scientists attribute this rise to the increased concentration of greenhouse gases.During processing, the text is split into three lines and numbered as [0], [1], and [2], respectively. This numbering method facilitates subsequent segmentation and processing and provides an accurate reference for semantic analysis.
Structured Segmentation Based on Large Language Models (LLMs)
After the document is split and numbered by line, a large language model (LLM) is used to perform structured segmentation of the document. The LLM divides the document into several parts based on the actual semantics and logical structure, with each part focusing on a specific topic or concept.
During this process, the LLM not only analyzes the text’s semantics but also generates the start and end positions for each part based on line number information. This structured segmentation process relies on specific prompt design, ensuring that the segmentation results are highly consistent with the document’s natural logic. Specifically, the prompt we used is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28system_prompt = """
**Task: Structured Document Creation**
You are provided with a document that includes line numbers. Your task is to create a StructuredDocument object by dividing the document into several sections. Each section should focus on a specific topic or concept. Please follow the instructions below carefully:
**Document Division:**
- Divide the document into several sections based on its content. Each section should discuss a single topic or concept.
- The sections should align as closely as possible with the document's natural divisions, such as "Introduction," "Background," "Discussion," "Conclusion," etc.
**Line Number Annotation:**
- For each section, note the starting and ending line numbers.
- The start_index should be the line number of the first line in that section, and the end_index should be the line number of the last line in that section. For example, if a section begins at line 5 and ends at line 10, the start_index should be 5, and the end_index should be 10.
**Complete Coverage of the Document:**
- Ensure that all sections together cover the entire document without any gaps or overlaps.
- The first section should begin at the document's first line, and the last section should end at the document's last line. No lines should be left out, and no sections should overlap.
**Section Titles:**
- Create a concise and descriptive title for each section, allowing the reader to grasp the main content of the section just by reading the title.
**Judgment and Flexibility:**
- Note that this document might be an excerpt from a larger document. Therefore, do not assume that the first line is necessarily an "Introduction" or the last line is a "Conclusion."
- You must make a reasonable division based on the actual content and assign an appropriate title to each section.
The final goal is to produce a StructuredDocument where each section focuses on a specific topic, with accurately marked line number ranges, to clearly and comprehensively reflect the document's content structure.
"""Iterative Processing of Long Documents
For lengthy documents, it is usually impossible to complete the entire segmentation process in one pass. Therefore, an iterative processing method is employed. By calling the LLM multiple times, processing one part of the document at a time, the entire document is gradually segmented. This approach ensures that even when dealing with ultra-long documents, the system can effectively perform semantic segmentation, ensuring the integrity and coherence of each part.
Verification and Correction of Segmentation Results
After completing all segmentation operations, the segmentation results must be verified to ensure that they seamlessly cover the entire document. Any overlapping, omitted, or discontinuous parts will be adjusted during the correction process to generate the final, structured document segmentation. This step ensures the accuracy and reliability of the segmentation results, laying a solid foundation for subsequent processing.
Example
Document Content:
1 | [1] Climate change is one of the most pressing issues of our time. |
Structured Document Example:
1 | { |
Overall, Context Segmentation plays an irreplaceable role in processing unstructured text data. By reasonably dividing document content into multiple semantically clear parts, Context Segmentation provides the necessary semantic framework for subsequent context generation and paragraph integration and significantly improves the precision and efficiency of text processing. Through this structured segmentation method, the system can more accurately understand the inherent logic of the text, thereby improving information retrieval and generation effectiveness.
Part 2: Context Generation
In processing unstructured text data, in addition to effectively segmenting the document into semantic parts, it is also essential to generate precise contextual information for each text fragment to support the system’s deep semantic understanding and efficient information retrieval. Context Generation achieves this by generating titles, summaries, and context blocks for each document section, helping the system better capture the core content and semantic relationships of the text, providing a solid semantic foundation for subsequent embedding and retrieval processes.
Detailed Steps of Context Generation
Document Title Generation
Generating an accurate and concise document title is crucial when processing unstructured text. The document title not only quickly conveys the document’s theme but also provides a semantic anchor for subsequent context generation and paragraph integration. The system first generates a title based on the document content, a process that relies on the large language model’s (LLM) analysis of the text content.
We use the following prompt to generate the document title:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16DOCUMENT_TITLE_PROMPT = """
INSTRUCTIONS
Please provide the title of the document based on the content provided below.
IMPORTANT:
- Your response must ONLY be the title of the document.
- Do NOT include any additional text, explanations, or comments.
{document_title_guidance}
{truncation_message}
DOCUMENT CONTENT:
{document_text}
""".strip()When generating the document title, the system first extracts the first few thousand words of the document and passes this content to the LLM. The LLM generates a title that summarizes the main theme of the document based on the provided text content. The generated title must be concise and clear, accurately reflecting the core content of the document.
Document Summary Generation
The document summary is an important part of information retrieval and text generation tasks. By generating a document summary, the system can quickly grasp the core content of the document, thereby enhancing retrieval accuracy. The generation of the document summary also relies on LLM’s semantic analysis.
The prompt for generating the document summary is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23DOCUMENT_SUMMARIZATION_PROMPT = """
INSTRUCTIONS
Please summarize the content of the document in a single, concise sentence.
IMPORTANT:
- Your summary should begin with: "This document is about: "
- The sentence should be clear and to the point, covering the main topic of the document.
- Do NOT add any additional information or context beyond the main topic.
Example Summaries:
- For a history book titled "A People's History of the United States," you might say: "This document is about: the history of the United States, covering the period from 1776 to the present day."
- For the 2023 Form 10-K of Apple Inc., you might say: "This document is about: the financial performance and operations of Apple Inc. during the fiscal year 2023."
{document_summarization_guidance}
{truncation_message}
DOCUMENT TITLE: {document_title}
DOCUMENT CONTENT:
{document_text}
""".strip()Through specific prompts, the system guides the LLM to generate a concise document summary, typically in one sentence, directly pointing out the document’s main content or theme. The document summary not only provides a global semantic context for the system but also offers necessary support for subsequent context generation.
Section Summary Generation
For long documents divided into multiple parts, generating a summary for each part is especially important. Section summaries help the system understand the text’s semantic structure at a finer granularity, thereby improving accuracy in retrieval and generation tasks. (Section titles have already been generated during Part 1 segmentation)
The prompt we use for section summary generation is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23SECTION_SUMMARIZATION_PROMPT = """
INSTRUCTIONS
Please summarize the content of the following section in a single, concise sentence.
IMPORTANT:
- Your summary should begin with: "This section is about: "
- The sentence should clearly describe the main topic or purpose of this section.
- Do NOT add any additional information or context beyond the main topic of the section.
Example Summary:
- For a balance sheet section of a financial report on Apple, you might say: "This section is about: the financial position of Apple as of the end of the fiscal year."
- For a chapter on the Civil War in a history book, you might say: "This section is about: the causes and consequences of the American Civil War."
{section_summarization_guidance}
SECTION TITLE: {section_title}
DOCUMENT TITLE: {document_title}
SECTION CONTENT:
{section_text}
""".strip()Through this prompt, the system can generate a brief summary for each section, clearly indicating the main content and purpose of that section. This fine-grained semantic understanding is particularly important for processing long, complex documents.
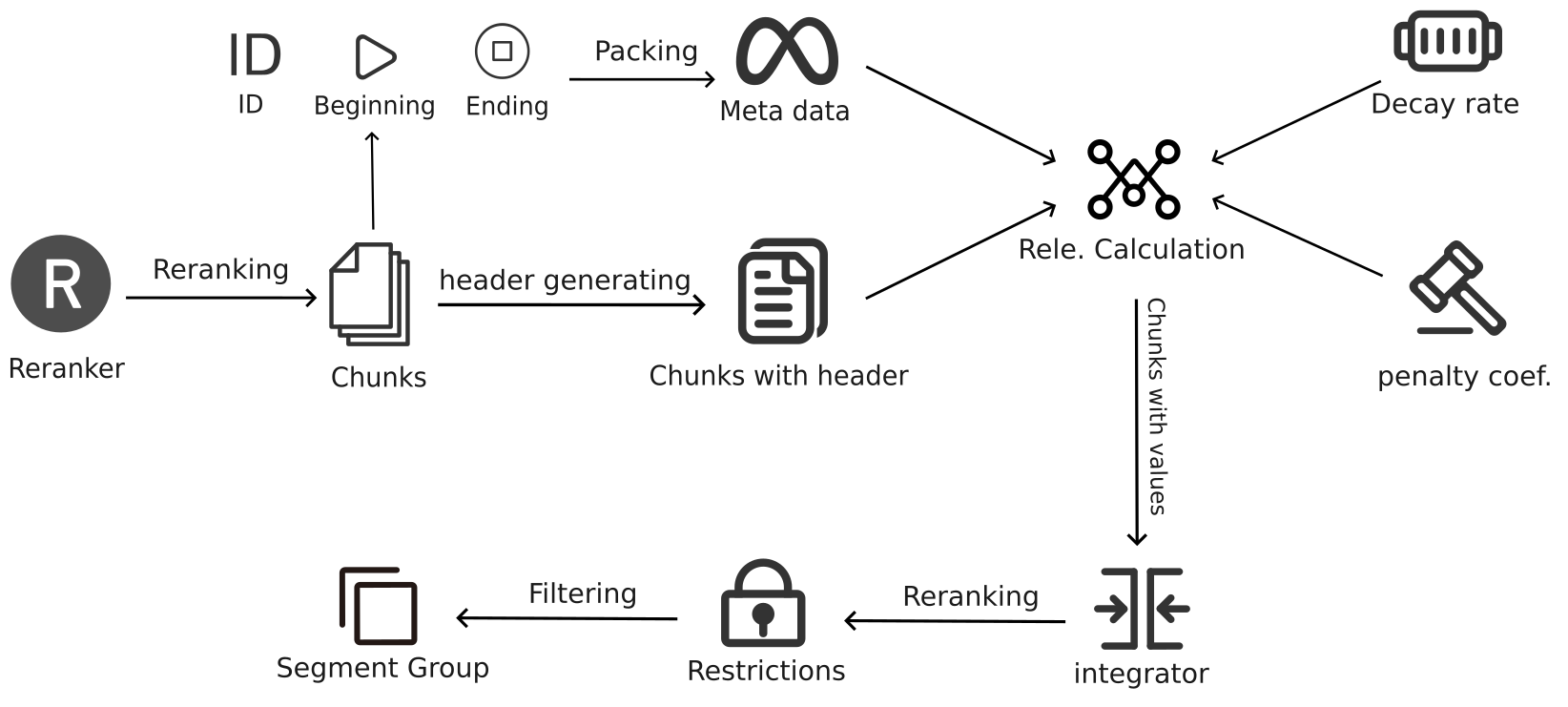
Flowchart
The flowchart developed during this process is as follows:

Example
Document Content:
The document is an extensive report on the various effects of climate change on polar bear populations in the Arctic. The report is divided into several sections:
- Introduction: This section provides an overview of the current status of polar bears and the key challenges they face due to climate change. It introduces the main themes of the report, such as habitat loss, changing prey availability, and the impact of human activities.
- Melting Sea Ice: This section discusses the drastic reduction in sea ice in the Arctic, which serves as a critical habitat for polar bears. It explains how the loss of sea ice has affected polar bear hunting behaviors, forced them to migrate longer distances, and led to a decline in their overall population.
- Impact on Prey Availability: This section examines how climate change has disrupted the availability of prey for polar bears, particularly seals. It discusses the cascading effects on the polar bear food chain and how changes in prey distribution are leading to malnutrition and decreased reproductive rates among polar bears.
- Human Activities and Pollution: This section explores how human activities, including oil drilling, shipping, and pollution, are further exacerbating the challenges faced by polar bears. It discusses the potential long-term effects of pollutants on polar bear health and how industrial activities are encroaching on their habitats.
5
. Conservation Efforts and Future Strategies: This section reviews current conservation efforts aimed at protecting polar bears and their habitats. It also proposes future strategies that could mitigate the impact of climate change, such as reducing greenhouse gas emissions, protecting critical habitats, and developing new conservation policies.
6. Conclusion: The conclusion summarizes the key findings of the report and emphasizes the urgent need for coordinated global efforts to protect polar bears in the face of ongoing climate change.
Context Generation
1 | # Step 1: Document Title Generation |
Overall, by generating document titles, document summaries, section summaries, as well as context blocks and paragraph headers, the system can understand the semantic structure of the text at multiple levels and provide the necessary contextual information for each text block. This process not only enhances the system’s performance in information retrieval and text generation tasks but also lays a solid foundation for semantic processing across the entire system.
In the subsequent sections, we will further explore the technical details of Chunks Integration and analyze how these technologies play a role in complex text processing tasks. Through these analyses, you can gain a more comprehensive understanding of how TextRAG optimizes text processing through context generation, achieving efficient semantic understanding and information integration.
Part 3: Reranking
In processing unstructured text data, initial search results are typically based on the similarity of embedding vectors, selecting text blocks (chunks) related to the query. However, this vector-based initial ranking may not fully capture the deep semantics of the query, leading to situations where some text blocks appear relevant on the surface but may deviate from the user’s query in actual semantics. To further enhance the accuracy and relevance of retrieval results, the Reranking step becomes an indispensable part of the process.
Reranking Details
In the initial stage of text block retrieval, TextRAG screens the most relevant top-k chunks from the database based on the similarity of embedding vectors. These initially selected chunks reflect preliminary similarity to the query, but may have limitations when dealing with complex semantics, especially when processing highly semantic text. To address these issues, the Reranking step re-analyzes and reranks the initially selected text blocks using more refined language models (e.g., Cohere or VoyageAI) to better capture the semantic relationship between the text blocks and the query.
During the Reranking process, TextRAG first uses an advanced language model to conduct a more in-depth evaluation of the top-k text blocks relative to the query. Each text block is reassigned a new relevance score and reordered based on the new score. These scores are then transformed using a specific transformation function to uniformly distribute them between 0 and 1. This transformation, achieved through a Beta distribution function, ensures the balance and sensitivity of the score distribution, allowing TextRAG to more precisely distinguish subtle differences between text blocks. After reordering, although the text blocks remain the same as the initially selected chunks, their order, scores, and ranking have been adjusted to better reflect their actual semantic relevance to the query.
Why Transform the Score?
Transforming the relevance score into a uniform distribution between 0 and 1 is a key step in the Reranking process. This transformation, achieved through a Beta distribution function, aims to avoid overly extreme score distributions, thereby enhancing the reliability of the Reranking results. This uniform score distribution ensures that during the subsequent Chunks Integration process, the relevance scores of the various text blocks can be reasonably and effectively considered.
Specifically, during the block integration process, TextRAG needs to combine multiple reranked text blocks into coherent fragment combinations. The uniform distribution of scores ensures that these text blocks can be more precisely ranked and selected based on their actual semantic relevance. In this way, during paragraph integration, TextRAG can more effectively arrange and combine text blocks to form semantically coherent and information-dense paragraphs, further enhancing the overall performance of the system.
Reranking is not only an important step to improve the accuracy of text retrieval but also lays a solid foundation for subsequent block integration. By transforming relevance scores into a distribution between 0 and 1, TextRAG ensures that the scores of each text block are more distinctive, allowing for more precise arrangement and selection of text blocks during block integration. This process greatly enhances the system’s ability to handle complex queries, ensuring that the final generated content is both coherent and highly relevant.
In the following Chunks Integration section, we will explore in detail how these reranked text blocks are integrated into more coherent and semantically rich fragment combinations, and how further supplementation of contextual information improves TextRAG’s overall performance in text generation and information retrieval.
Part 4: Chunks Integration
In processing unstructured text data, TextRAG divides documents into chunks, breaking them down into smaller textual units to enable more granular information retrieval and analysis. However, the chunking process itself presents certain challenges: if the chunks are too small, the text’s context may be severed, leading to semantic loss; if the chunks are too large, they may contain too much irrelevant information, affecting retrieval accuracy. Particularly when dealing with complex, broad queries, a single chunk is often insufficient to provide a complete answer, which brings up the crucial step of Chunks Integration, aimed at ensuring the system returns results that are both complete and accurate by integrating multiple text blocks.
Why Chunks Integration?
In text retrieval, chunking directly affects the quality of the final results. Both overly small and overly large chunks have their drawbacks:
- Drawbacks of Overly Small Chunks:
- Semantic Fragmentation: When the text is split too finely, the original coherent context is interrupted. For instance, when discussing complex theories or historical events, key information may be dispersed across multiple chunks, making a single chunk unable to provide a complete background and logic.
- Incomplete Information: Small chunks may only contain part of the relevant information, making it impossible to provide a complete answer. This forces the user to gather multiple chunks to understand the entire content, increasing the complexity of the query results.
- Low Retrieval Efficiency: Because information is dispersed across multiple small chunks, the system needs to spend more computational resources and time processing and integrating these chunks, reducing retrieval efficiency.
- Drawbacks of Overly Large Chunks:
- Increased Noise: Larger chunks often contain a lot of irrelevant information, which can interfere with the presentation of core content, reducing the accuracy of retrieval results.
- Difficulty in Precise Matching: When chunks are too large, the system may find it challenging to find content that precisely matches the query, possibly returning chunks with a lot of irrelevant content, making the results less accurate.
- Information Redundancy: Larger chunks may repeatedly contain content unrelated to the query, making the results appear lengthy and difficult to extract key information from, affecting user experience.
These issues are particularly pronounced when handling complex queries. For example, for a simple query like “What is Shakespeare’s birth year?” a single text block can accurately answer because the information is concentrated and clear. However, for more complex and broad questions, a single text block may not provide a comprehensive answer.
Consider a question like “What are the passages in Hamlet that describe the tragic fate?” This question requires extracting multiple passages scattered across different scenes of the play. If the chunks are too small, the answer will be fragmented into multiple incoherent parts; if the chunks are too large, the answer may include too much irrelevant plot description, causing the answer to lose focus.
Similarly, consider a historical question like “What were the main factors leading to the outbreak of the Pearl Harbor incident during World War II?” Such a query involves a complex historical background, and the answer may need to draw information from different parts of the literature. For example, the causes may be located at the beginning of the document, while the consequences and summaries may appear at the end. In this case, relying solely on a single text block cannot provide a comprehensive perspective, leading to a partial or inaccurate answer.
For these reasons, Chunks Integration becomes particularly important. For complex queries, returning just one or two chunks may not provide a complete answer and may result in inaccurate or partial answers. By integrating related chunks,
TextRAG can generate a semantically coherent and information-complete paragraph, ensuring that the answers to complex queries are both comprehensive and precise. This integration process ensures that the system, when faced with complex queries, can synthesize multiple relevant text blocks to provide a detailed and well-organized answer, thus enhancing the quality of information retrieval and user satisfaction.
Implementation Details
Chunks Integration is a critical step in the TextRAG system, optimizing the algorithm to integrate multiple relevant text blocks into semantically coherent and information-complete paragraphs. Below are the detailed implementation steps and an overall architecture diagram:
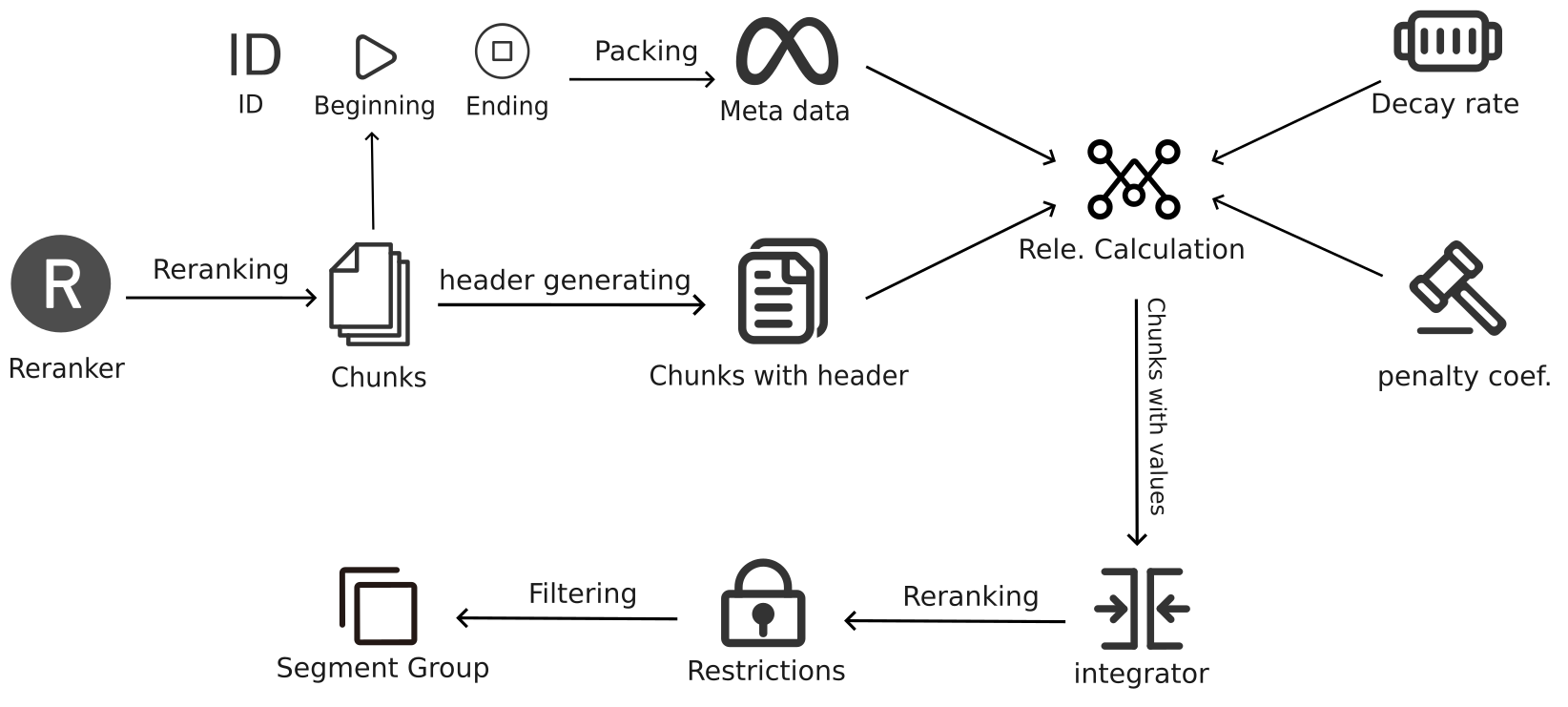
1. Building the Meta-document
In the first step of Chunks Integration, the system extracts the start points, end points, and chunk IDs of each text block from the reranked results, and constructs a meta-document from this information. This meta-document does not contain the actual text content but is an index structure recording the positions of various related text blocks in the document. This index structure provides the basis for subsequent paragraph integration, ensuring that the system can accurately identify and combine related text blocks during processing.
In this way, the system establishes a meta-document containing all the relevant text blocks, clarifying each block’s position and relative relationship in the entire document, thereby laying a solid foundation for subsequent paragraph integration.
2. Evaluating the Relevance of Text Blocks
After constructing the meta-document, the system needs to evaluate the relevance value of each text block. This step receives multiple input parameters, including all parameters in the meta-document, reranked results, irrelevant chunk penalties, and decay rates. These parameters collectively determine the matching degree of the text block with the query. The following describes this process in detail.
Input Parameters:
- Meta-document Parameters: Including the start point, end point, and chunk ID of each text block.
- Reranked Results: These results contain the rank and absolute relevance value of each text block.
- Irrelevant Chunk Penalty: Used to control the length of the paragraph generated during the integration process. The larger the penalty, the shorter the generated paragraph.
- Decay Rate: Determines the impact of the rank on the relevance value.
Relevance Score Calculation:
In calculating the relevance score of a text block, the system uses theget_chunk_valuefunction. The specific steps are as follows:First, retrieve the
rankandabsolute_relevance_valuefromchunk_info. If these values do not exist, the defaultrankis set to 1000, and theabsolute_relevance_valueis set to 0.0.Then calculate the text block score
v, with the formula:

The higher the
rank:

the smaller the value, meaning the score will decrease;The larger the
absolute_relevance_value, the higher the initial score of the text block;Finally, subtract an
irrelevant_chunk_penaltyas a penalty term.
Different penalty coefficients will affect the length of the generated paragraph:
- 0.05: Generates longer paragraphs, typically containing 20-50 blocks.
- 0.1: Generates long paragraphs with 10-20 blocks.
- 0.2: Generates medium-length paragraphs with 4-10 blocks.
- 0.3: Generates short paragraphs with 2-6 blocks.
- 0.4: Generates very short paragraphs with 1-3 blocks.
In this way, the system can dynamically adjust the length and relevance of paragraphs, ensuring that the generated paragraphs contain sufficient information while not being overly lengthy.
Length Adjustment:
After calculating the initial relevance value, the system further adjusts the score of each text block based on its length. This step is implemented through theadjust_relevance_values_for_chunk_lengthfunction. The specific steps are as follows:Input Parameters:
relevance_values: The initial relevance value list calculated by theget_chunk_valuefunction.chunk_lengths: The corresponding length list (in characters) of each text block.reference_length: A reference length (default 700 characters) used to standardize text blocks of different lengths.
Calculation Process:
The system traversesrelevance_valuesandchunk_lengthsand adjusts the score of each text block. The specific formula is:

If a text block’s length exceeds the
reference_length, its score will be amplified;If the text block’s length is less than the
reference_length, its score will be reduced.
This adjustment ensures that longer text blocks can achieve higher scores during the integration process, while shorter text blocks receive lower scores, balancing the influence of text blocks of different lengths during the integration process.
The purpose of these adjustment processes is to allow the system to more accurately evaluate the value of each text block by considering its length and relevance, thereby selecting the most valuable combination of text blocks during the subsequent paragraph integration process. This method ensures that the final generated paragraph achieves the best results in terms of information density and semantic coherence.
3. Selecting the Optimal Fragment Combination: Application of Optimization Algorithms
After evaluating the relevance scores of all chunks, the TextRAG system applies optimization algorithms to generate multiple optimal fragment combinations (Segment Grouping). This process is crucial as it determines whether the final content returned to the user can accurately and comprehensively answer complex queries. Therefore, the system performs precise combination optimization based on multiple constraints. The detailed steps are as follows:
Input Parameters
The input to the optimization algorithm includes the relevance scores calculated in the previous step and several key constraints. These parameters determine which chunks will be selected and how they will be combined into fragment combinations:
- Relevance Scores: These are the scores calculated from the previous steps, reflecting each chunk’s matching degree with the query, serving as the core basis for the optimization algorithm to select chunks. Before this step, each chunk has been added with contextual information through the
get_chunk_headerfunction, including the document title, document summary, section title, and section summary, ensuring that chunks have a complete semantic background during the calculation and selection process. - Constraints:
- Maximum Combination Length (max_length): Specifies the maximum number of chunks that can be included in a single fragment combination. This constraint prevents the generated fragment combination from being too long, ensuring that the information is focused and coherent.
- Overall Maximum Length (overall_max_length): Limits the total length of all fragment combinations, preventing the returned content from being overly lengthy.
- Minimum Relevance Threshold (minimum_value): Ensures that only chunks reaching or exceeding this score are considered for integration, thereby excluding irrelevant or low-relevance content.
Optimizing the Combination of Chunks
Upon receiving the relevance scores and constraints, the system begins optimizing the combination of chunks, generating one or more fragment combinations (Segment Grouping):
- Traversing Relevance Scores: The system traverses all the relevance scores of the query, searching for the highest-scoring chunks and combining them. The combination of these chunks forms a fragment combination that can collectively provide the required information for the query.
- Checking Constraints: While generating fragment combinations, the system strictly adheres to the following constraints:
- Maximum Chunks Limit: The number of chunks in each fragment combination must not exceed
max_length. If a combination exceeds this limit, the system stops adding chunks to that combination and starts creating a new fragment combination. - Document Source Limit: To maintain the semantic coherence of the fragment combination, all chunks in a combination must come from the same document. If the current chunk comes from a different document than the selected chunks, the system starts creating a new fragment combination.
- Overall Length Limit: The system accumulates the total number of chunks in all generated fragment combinations, ensuring that it does not exceed
overall_max_length. Once this limit is reached, the system stops creating new fragment combinations, even if there are still relevant chunks that have not been selected.
- Maximum Chunks Limit: The number of chunks in each fragment combination must not exceed
- Generating Multiple Fragment Combinations: The system may generate multiple fragment combinations, each containing chunks that are tightly related and semantically coherent. These combinations will collectively provide a complete answer to the query. During this process, the generated fragment combinations will also be added with contextual information, such as document titles and summaries, using the
get_segment_headerfunction, to provide complete semantic backgrounds for subsequent processing.
Parameter Selection and Adjustment
The selection of parameters has a significant impact on the generation of fragment combinations, and different application scenarios require different parameter settings:
- Maximum Combination Length (max_length): If the query requires a broader context, a larger
max_lengthcan be chosen to include more chunks; for queries requiring precise answers, a smallermax_lengthis more appropriate. - Overall Maximum Length (overall_max_length): This parameter is usually set according to the expected response length. For short answers,
overall_max_lengthshould be set smaller; for queries requiring detailed answers, a larger value can be chosen. - Minimum Relevance Threshold (minimum_value): This is usually set at a higher level to exclude noisy content. However, for queries requiring broader information, this value can be appropriately lowered to include more content.
The selection of these parameters is typically determined through experimentation and adjustment to achieve the best balance. For example, when dealing with complex queries requiring the integration of large amounts of information, max_length and overall_max_length can be increased, and `minimum
_value` lowered to include more chunks. Conversely, for queries requiring precise and concise answers, the parameters can be adjusted in the opposite direction.
Segment Grouping
After completing all possible combination calculations, the system returns the highest-scoring one or more fragment combinations (Segment Grouping). The chunks within these combinations satisfy all constraints and maximize the integration of relevant information, ensuring that the content is both coherent and complete.
Through this optimization algorithm, the TextRAG system can generate semantically coherent, information-dense fragment combinations for complex queries. This process resolves the potential issues of information fragmentation and semantic fragmentation that simple chunk retrieval may cause, ensuring that the final generated content can provide users with comprehensive and accurate answers, providing strong support for TextRAG’s excellent performance in complex information retrieval tasks.
Flowchart
The flowchart of this module developed during the process is as follows:

Evaluation
This section aims to detail the evaluation experiment process of the TextRAG system. We selected the FINANCEBENCH dataset as the primary evaluation benchmark and validated TextRAG‘s performance in handling complex financial information queries through rigorous experimental design.
FINANCEBENCH
FINANCEBENCH is a benchmark dataset specifically designed to evaluate the performance of language models in financial question-answering tasks. The dataset covers 10,231 questions related to publicly listed companies, with content spanning across the following three main categories:
- Domain-Related Questions: These questions primarily involve basic indicators in corporate financial analysis, such as revenue and net profit, testing the model’s ability to handle standard financial data.
- Newly Generated Questions: These questions are more complex in design, aiming to test the model’s semantic understanding and reasoning abilities, especially when dealing with multi-layered information.
- Indicator Generation Questions: These questions require the model to calculate and reason about financial indicators, testing its comprehensive analytical capabilities.
This benchmark aims to evaluate language models’ abilities in information retrieval, semantic understanding, and reasoning through challenging financial question-answering tasks, thereby setting a minimum performance standard for models applied in the financial domain.
Evaluation Experiment Design for TextRAG
To validate TextRAG‘s effectiveness in handling complex financial information queries, we designed a series of experiments encompassing the entire process from knowledge base construction to final answer generation.
- Knowledge Base Construction
- Document Collection and Preprocessing: We collected a large number of documents (e.g., 10-K and 10-Q) from the financial reports of publicly listed companies. These documents were preprocessed, split into multiple chunks by line, and embedded into the knowledge base.
- Knowledge Base Generation: Using the Cohere embedding model, we converted the processed document fragments into queryable data in the knowledge base. The knowledge base construction was carried out under a shared vector store configuration, allowing multiple queries to efficiently access the same vector data simultaneously, greatly improving retrieval efficiency and system scalability.
- Automatic Query Generation
- Query Generation: For each question, up to six specific search queries were automatically generated using a large language model (e.g., Claude 3). These queries were designed to be precise enough to locate the most relevant information fragments within the documents.
- Query Optimization: The generated queries were further optimized to ensure their efficiency and relevance, allowing the system to retrieve the most accurate content.
- Retrieval and Response Generation
- Contextual Retrieval: The system executed the generated queries within the knowledge base, extracting text fragments relevant to the questions and integrating these fragments into a complete context. Through multi-layered retrieval and integration, the system could generate the necessary background information for complex questions.
- Final Response Generation: Using the GPT-4-Turbo model, the final answer was generated based on the retrieved context. The generation process focused on the brevity and accuracy of the answer, ensuring that it fully addressed the user’s query.
- Experimental Results and Analysis
- Result Comparison: The system-generated answers were compared with the standard answers provided by FINANCEBENCH, calculating the model’s accuracy and recall. The experimental results showed that under the Shared Vector Store configuration, TextRAG achieved an answer accuracy of 79%, significantly higher than the baseline model’s accuracy of 19%.
- Manual Evaluation: A manual review was conducted on some complex queries to further verify the system’s performance in multi-document retrieval and information integration.
- Performance Metrics Evaluation: Precision, recall, and other performance metrics were calculated to quantify TextRAG‘s performance in financial question-answering tasks and comprehensively compared with the baseline model.
Experiment Summary and Future Work
This evaluation experiment demonstrated that TextRAG performed excellently in complex financial question-answering tasks under the Shared Vector Store configuration. Its answer accuracy reached 79%, significantly higher than the baseline model’s 19%. These results prove TextRAG‘s advantages in handling complex semantic queries and multi-document integration, especially in its practical application in the financial domain, showing significant value and potential.
In the future, we plan to conduct more precise evaluations of the system’s recall rate, precision, and other performance metrics to further optimize TextRAG‘s performance. Through these follow-up studies, TextRAG will be better equipped to handle diverse query needs, providing more comprehensive and reliable answers.
(To be continued…)
Reference
[A long waiting list …]