© Wuyuhang, 2024. All rights reserved. This article is entirely the work of Wuyuhang from the University of Manchester. It may not be reproduced, distributed, or used without explicit permission from the author. For inquiries, please contact me at yuhang.wu-4 [at] postgrad.manchester.ac.uk.
Background
Tables, as a fundamental and widely used semi-structured data type, are prevalent in relational databases, spreadsheet applications, and programming languages used for data processing. They cover a range of fields such as financial analysis (Zhang et al., 2020; Li et al., 2022), risk management (Babaev et al., 2019), and healthcare analytics. In these applications, table-based question answering (TableQA) is a key downstream task for reasoning over tabular data (Ye et al., 2023a; Cheng et al., 2023).
The goal of TableQA is to enable computers to understand human queries about table contents and respond with natural language answers. With the rapid development of large-scale language models (LLMs) in recent years, TableQA has emerged as an important subfield and has made significant progress (Ray, 2023). Currently, most research leveraging LLMs for TableQA is based on single tables (Li et al., 2023). These approaches typically involve preprocessing the table, then inputting the question and the table into the LLM, focusing on improving the LLM’s understanding of table structure. Such methods are primarily applied in practical contexts within the financial sector, such as financial table question answering, financial audit table processing (Zhu et al., 2021), and financial numerical reasoning (Chen et al., 2021; Chen et al., 2020). However, in real-world scenarios, the challenge often involves a set of tables rather than a single table, where users may pose arbitrary questions related to multiple tables. In these cases, the LLM needs not only to input tables one by one but also to retrieve relevant tables from a large collection and provide answers. However, research in this area is still relatively lacking, and our research aims to fill this gap.
Fine-tuning large-scale language models is a common approach to address the challenges of TableQA, but this method requires large amounts of domain-specific labeled data and significant computational resources. Moreover, most models, when handling domain-specific and complex tabular data, often overly rely on pre-trained knowledge, leading to hallucinations and incorrect information (Ray, 2023; Gao et al., 2023).
To address these challenges, retrieval-augmented generation (RAG) methods combine retrieval mechanisms with generative models, referencing external knowledge bases to reduce model hallucination and improve the accuracy of domain-specific question answering while reducing resource consumption (Gao et al., 2023). However, despite the strong performance of RAG in handling unstructured text data, there are several challenges when applying it to semi-structured tabular data. Specifically, we identified the following three limitations:
- The tables required to answer questions may be very large, containing a significant amount of noise unrelated to the query (Lu et al., 2024). This not only increases unnecessary computation but also affects the accuracy of retrieval and the generator’s response. To address this issue, we can employ table sampling (Sui et al., 2024) or table filtering methods to retrieve relevant rows and columns, thereby generating the most relevant sub-tables (Jiang et al., 2023).
- The original content of the tables may contain information that requires further clarification, such as domain-specific terms or abbreviations (Sui et al., 2024). These domain-specific details can lead to misunderstandings or biases in the generator. Additionally, we have found that many tables lack clear titles or detailed column descriptions, which makes it difficult to accurately map queries to the relevant tables or columns during retrieval, thereby affecting the effectiveness of retrieval and the accuracy of the generated results.
- Tables often contain various types of information across different columns, and traditional retrieval methods such as BM25 (Robertson et al., 2009) or Dense Passage Retriever (DPR) (Karpukhin, et al., 2020) may overlook table details, impacting the generated results. We can address this issue by employing the ColBERT model as a retriever, which encodes text at the token level, enabling more fine-grained retrieval (Li et al., 2023).
By incorporating these improvements, our research aims to provide a more effective solution for handling large-scale TableQA tasks involving multiple tables, addressing more complex real-world scenarios.
Overview
In tackling complex TableQA tasks, we designed a system that combines the latest large-scale language models (LLMs) with retrieval-augmented generation (RAG) techniques to handle multi-table issues in practical applications. Below is a graphical illustration and introduction of the core ideas of the project.
RAG-Based Multi-Table QA System Architecture
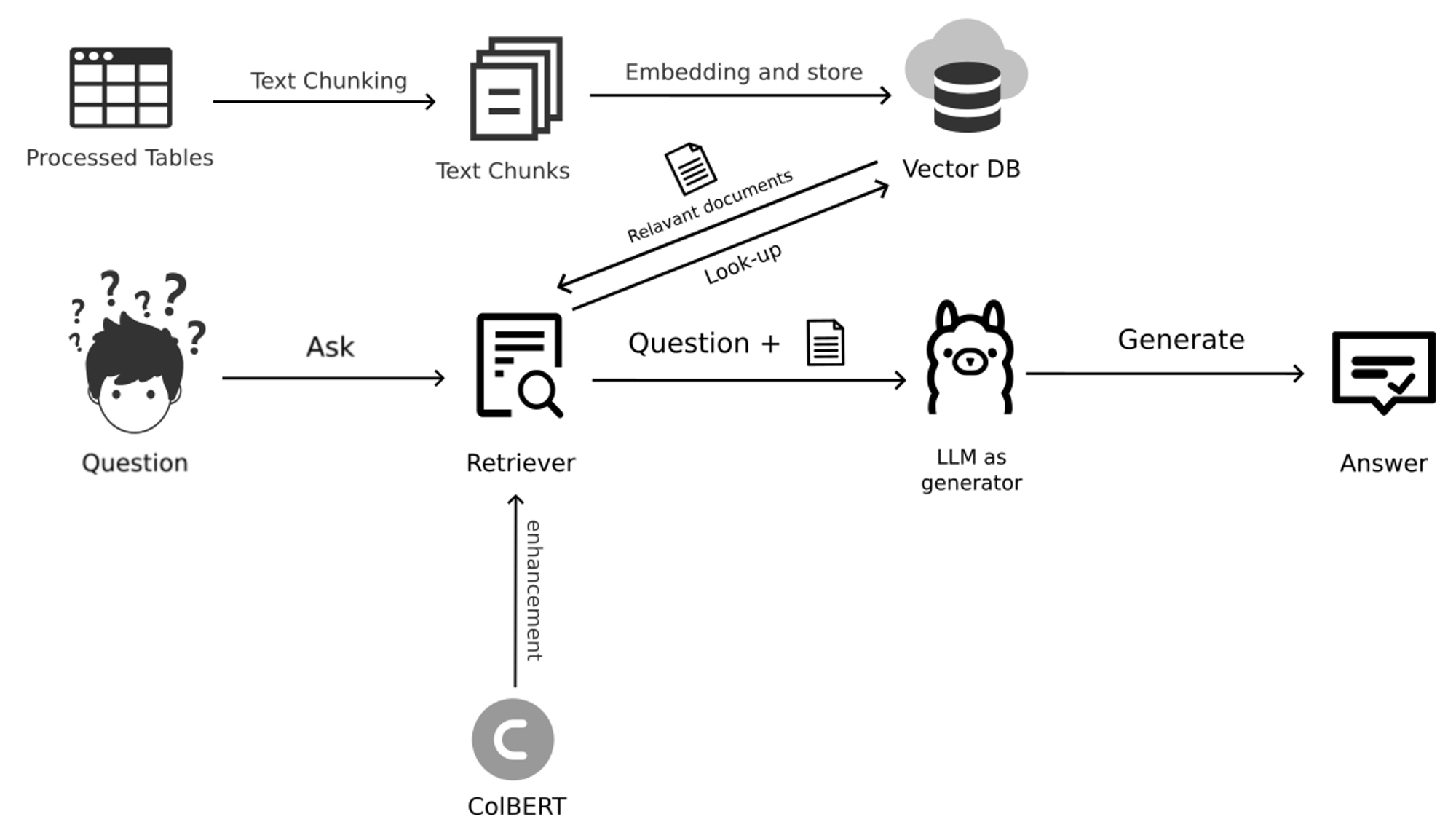
In this system architecture, our goal is to retrieve relevant information from multiple tables and generate accurate natural language answers. The process can be divided into the following key steps:
- Table Processing and Text Segmentation: First, the raw table data undergoes preprocessing and text segmentation, converting the table content into multiple text segments. The purpose of this is to make the data easier to handle and more efficiently retrieved for queries.
- Vector Database Construction: The segmented text and table fragments are embedded and stored in a vector database. The vector database, through efficient vectorized retrieval techniques, can quickly find the content fragments related to the query.
- Query and Retrieval: When a user poses a question, the retriever searches the vector database for table fragments related to the question. In this process, we introduce the ColBERT model to enhance the accuracy of the retriever. ColBERT encodes text at the token level, allowing for more fine-grained retrieval, thus improving the relevance of the retrieval results.
- Answer Generation: The retrieved relevant text fragments and the user’s question are input into a large-scale language model (LLM), which generates the final natural language answer.
Enhanced Mechanisms for Multi-Table QA
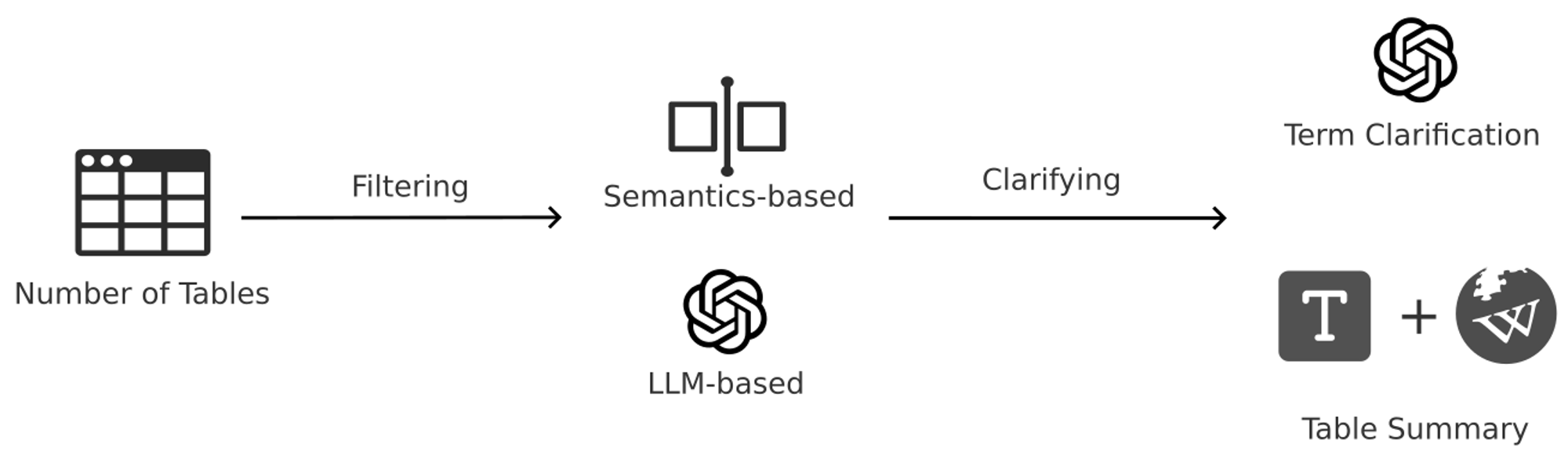
When handling data from multiple tables, our system introduces various enhancement mechanisms to improve the accuracy and effectiveness of the QA task.
Semantic-Based Table Filter: When dealing with a large number of tables, the system first filters the tables based on semantic analysis to select the most relevant ones. In this process, we used two different models for text embedding and comparison:
- Using OpenAI’s Embedding Model: We used OpenAI’s embedding model to embed the table content, then stored and retrieved the embedded data using the FAISS vector database, returning the table rows and columns most relevant to the query.
- Using the ColBERT Model: We also used the ColBERT model to embed the table content and performed more fine-grained retrieval during the search process. By comparing the results with those of the OpenAI Embedding model, we were able to select the semantic filtering method best suited to the specific task.
LLM-Based Filter: In addition to the semantic filter, we also used a large-scale language model (LLM) for intelligent table filtering. By analyzing the deep semantic relationship between the table content and the query, the LLM can more precisely select the most relevant table fragments, further improving retrieval accuracy.
Table Clarifier: Based on the filtered tables, we introduced two clarification modules:
- Term Clarification: For domain-specific terms or abbreviations in the table, we called the LLM for explanation, helping the LLM better understand the question and table content.
- Wiki-Based Summary Generation: First, we search Wikipedia for metadata related to the table title, header, or context. Then, we package this Wikipedia data with the original table context information to generate a summary related to the query or clarification statement. This approach not only improves the accuracy of information but also provides more comprehensive background support for understanding complex tables.
The above architecture and enhancement mechanisms effectively address the challenges present in current TableQA tasks, especially in the real-world application of multi-table environments. By combining advanced retrieval technology, semantic and LLM filtering, and large-scale language models, our system can quickly find relevant information from a large number of tables and generate accurate answers, providing strong support for various complex data analysis tasks.
Dataset Selection
Tablefact
In the existing TableQA datasets, we have conducted extensive attempts and research. For detailed dataset organization, please refer to my other blog: Dataset for Question Answering. Through these experiences, we found that when using datasets for retrieval-augmented generation in TableQA, we mainly face the following issues:
- Short Questions Lead to Poor Recall:
- Questions in many QA datasets are typically very short, consisting of only a few words. Such short queries often lead to poor recall of relevant tables in similarity-based retrieval or other dense retrieval processes.
- Uniform Question Format:
- Questions often begin with similar interrogative words and conjunctions. For example, in the SQA dataset, questions like “What are the schools?” and “What are the countries?” involve completely different content, but their opening “What are the” is the same. If the dataset contains nearly 500 questions beginning with “What are the,” this format repetition makes it very difficult to accurately recall relevant tables.
- Lack of Table Titles:
- A large number of QA datasets lack table titles, and typically, one table corresponds to one question, with no retrieval phase involved. In such cases, tables and questions are directly input together into the model. However, in the absence of table titles, accurately retrieving relevant tables from a large number of tables becomes much more difficult.
Based on these challenges, in our initial experiments, the TableFact dataset was our primary foundational dataset. The TableFact dataset focuses on the task of table fact verification, effectively evaluating a model’s reasoning and judgment capabilities.
TableFact is a large-scale dataset containing 117,854 manually annotated statements related to 16,573 Wikipedia tables. The relationships between these tables and statements are classified as “ENTAILMENT” and “REFUTATION.” This dataset first proposed evaluating language reasoning ability on structured data, involving a mix of symbolic and semantic reasoning skills. This complexity makes TableFact an ideal dataset for evaluating deep learning models’ ability to handle tasks that involve both semantic and symbolic reasoning.
| Channel | Sentence | Table |
|---|---|---|
| Simple (r1) | 50,244 | 9,189 |
| Complex (r2) | 68,031 | 7,392 |
| Total (r1 + r2) | 118,275 | 16,573 |
| Split | Sentence | Table |
| Train | 92,283 | 13,182 |
| Val | 12,792 | 1,696 |
| Test | 12,779 | 1,695 |
An example from this dataset is as follows:
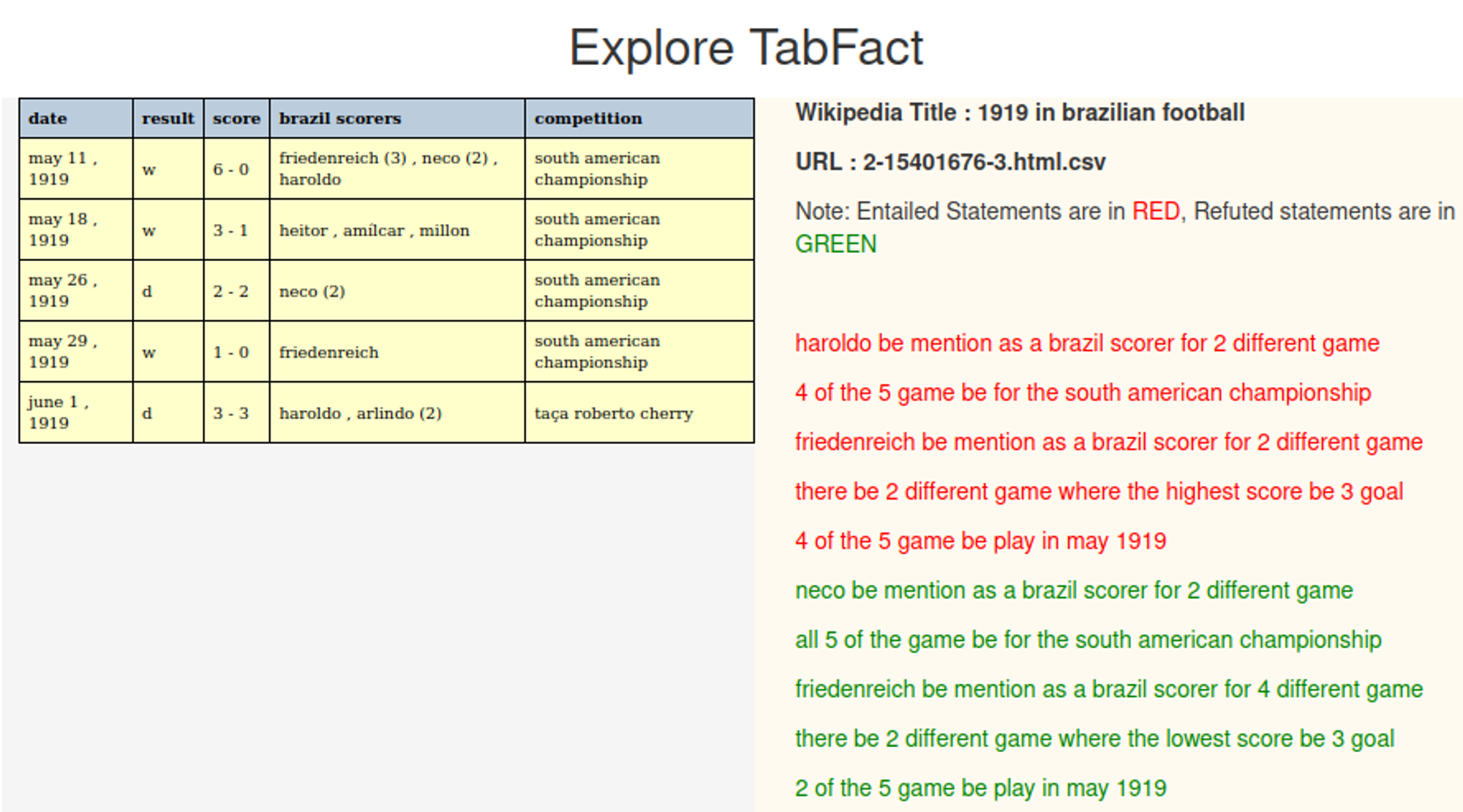
TableFact sample instances(Chen et al., 2019)
The primary advantage of the TableFact dataset lies in its focus on the task of table fact verification, effectively evaluating the model’s reasoning and judgment capabilities. The specific task is: given a table and a statement, the model is required to judge whether the statement is consistent with the information in the table. The model needs to deeply reason over the table content and mark the statement as “True” or “False.”
The TableFact dataset not only includes a large number of complex table and statement pairs, covering a wide range of domains and topics but also effectively simulates the multi-table QA scenarios that may be encountered in real-world situations. This provides us with a challenging test platform that helps us comprehensively evaluate and optimize our multi-table QA system. Another important reason for using this dataset is that it allows us to better control the output of the LLM, enabling us to precisely evaluate the model’s performance.
The reasons we chose to use the TableFact dataset are as follows:
- Pure Table Dataset: TableFact data is mainly presented in tabular form, with relatively low similarity between statements, making it relatively easier to accurately locate relevant information during retrieval.
- Clear Classification Task: The TableFact dataset’s task is clear: judging the truthfulness of statements. This task setting makes it easier to control the output of large models during answer generation, allowing us to more accurately evaluate the model’s reasoning ability.
Feverous
After using TableFact, we chose the FEVEROUS (Fact Extraction and VERification Over Unstructured and Structured information) dataset. FEVEROUS is a large-scale dataset specifically designed for fact verification tasks, which, unlike TableFact, contains not only structured tabular data but also unstructured text data. This makes FEVEROUS more complex and challenging in terms of retrieval and reasoning.
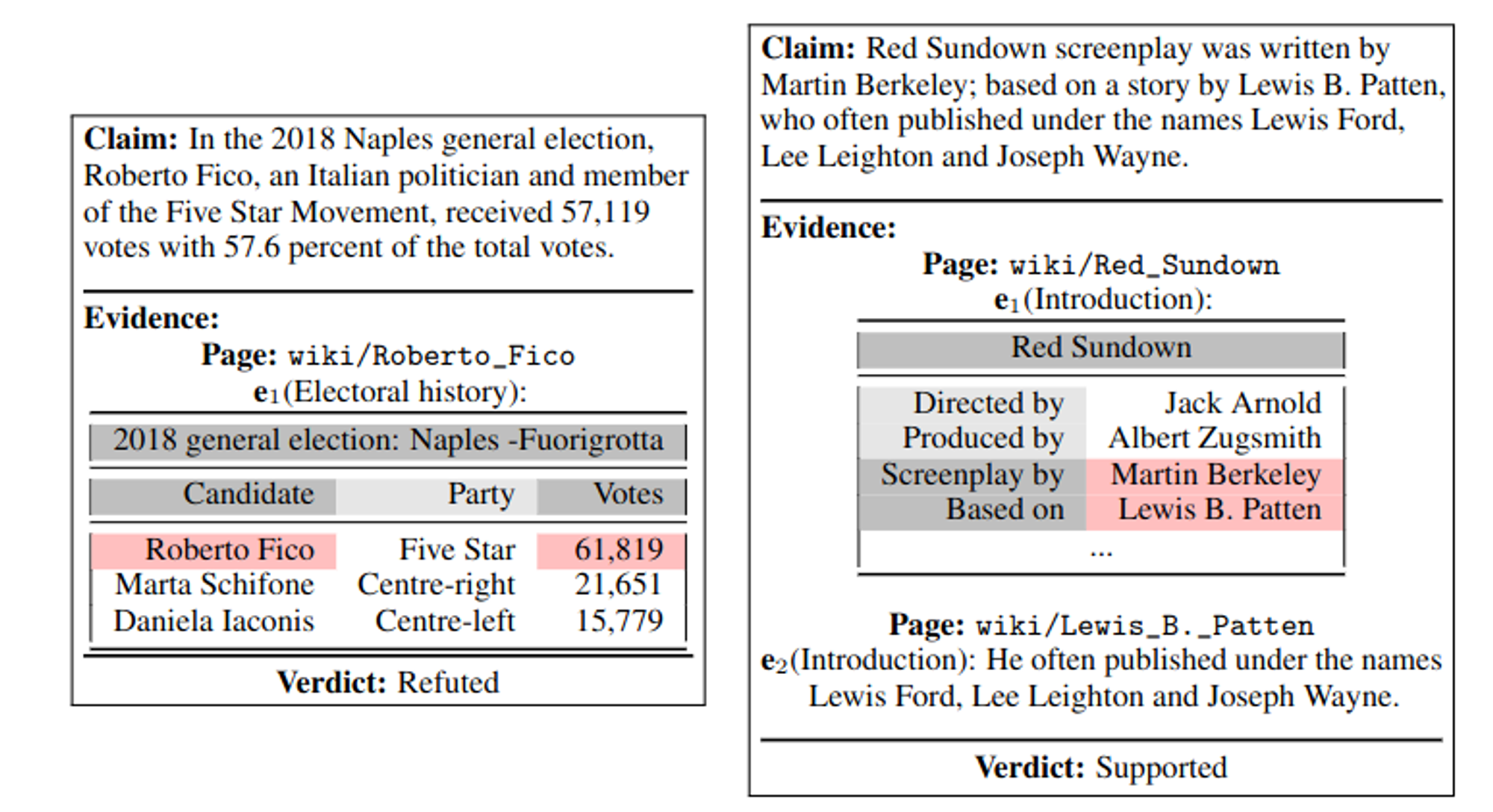
Feverous sample instances(Aly et al., 2021)
The FEVEROUS dataset contains over 80,000 table and text paragraph pairs, as well as more than 120,000 associated fact verification questions. When dealing with the FEVEROUS dataset, the model, in addition to judging the truthfulness of the statement, must also choose between three options: Supported, Refuted, or Not Enough Information. This three-choice task setup further increases the complexity of the model’s reasoning, making FEVEROUS a more comprehensive dataset for evaluating the model’s reasoning ability, especially in the integration and judgment of multi-source information.
Reasons for choosing FEVEROUS:
- Combining structured and unstructured data increases the difficulty of the model’s reasoning.
- The three-choice task setup allows for a better evaluation of the model’s performance in complex reasoning tasks.
SQA
In further expanding our experiments, we introduced the SQA (Sequential Question Answering) dataset. The SQA dataset is designed to evaluate the model’s performance in complex, multi-step QA scenarios. This dataset contains over 6,000 conversational QA pairs, with each conversation involving multiple related questions that are usually contextually linked to the previous Q&A. Unlike TableFact and FEVEROUS, SQA requires the model to maintain contextual understanding and consistency throughout a continuous Q&A process.
Questions in SQA not only require answering the current question but also require reasoning based on previous Q&A. Moreover, SQA requires the model’s answers to be freeform, covering various formats such as text, numbers, and more. This open-ended QA increases the model’s reasoning complexity and tests the model’s generative capabilities in handling freeform answers.

SQA sample instances (Lyyer et al., 2017)
Reasons for choosing SQA:
- Purely structured data, temporarily not involving the integration of two types of data.
- Focuses on multi-step QA, increasing the challenges for the model in handling conversational context and continuous reasoning.
- The introduction of freeform answers tests the model’s performance in open-ended QA tasks.
HybridQA
Finally, we chose the HybridQA dataset to further enhance the evaluation of the model’s multi-modal information processing capabilities. HybridQA is a dataset that integrates tabular and textual information, designed to test the model’s comprehensive QA capabilities over multi-modal information. The dataset contains 6,241 QA pairs, with each question involving content from multiple different information sources, including tables and associated unstructured text information.
The unique aspect of HybridQA is that the model not only needs to extract and integrate relevant information from multiple sources but also needs to involve numerical reasoning steps during the answering process. This multi-modal, multi-step QA format requires the model to excel in complex tasks, especially in cross-modal information integration and numerical reasoning.
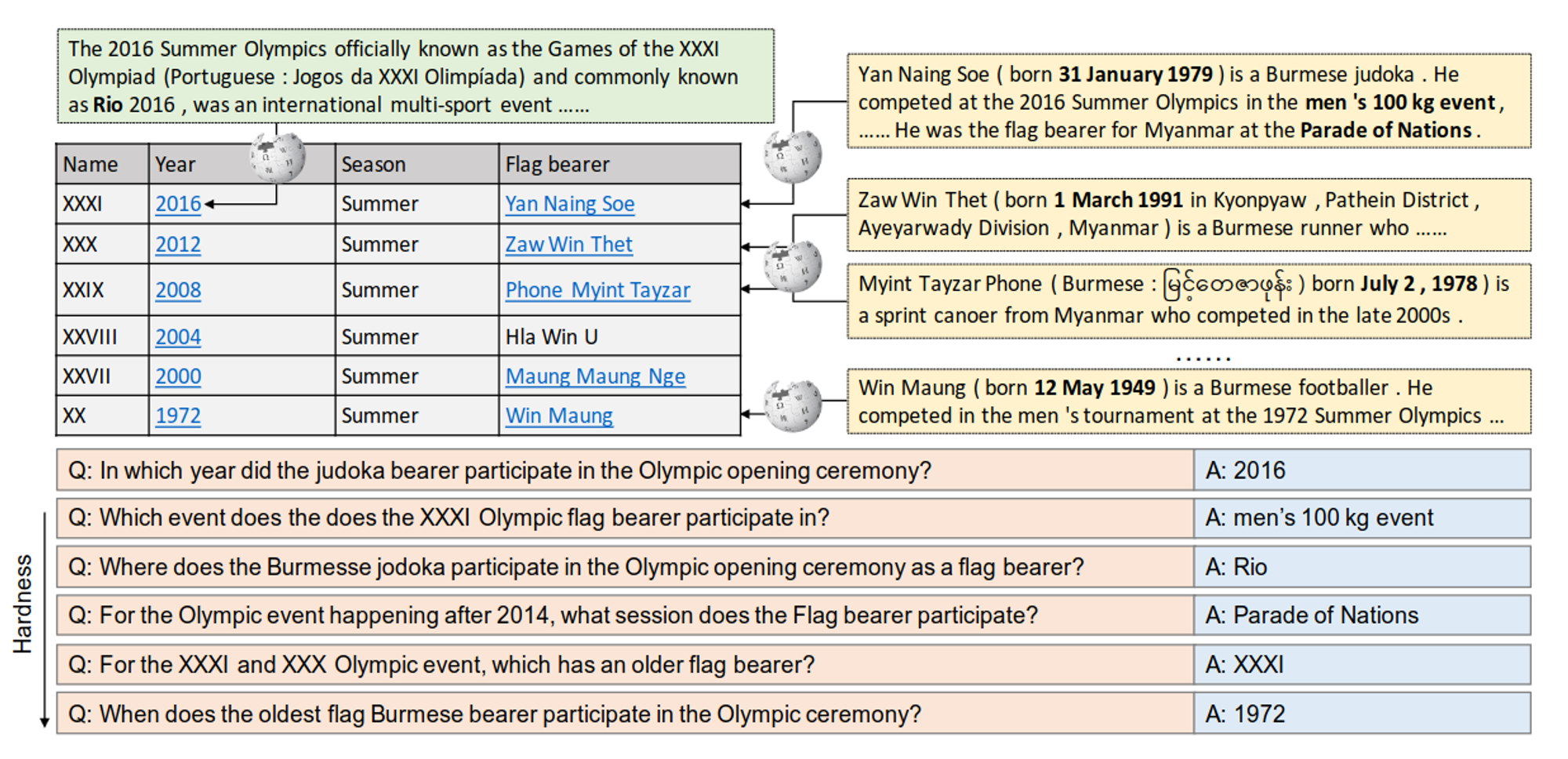
HybridQA sample instances (Chen et al., 2020)
Reasons for choosing HybridQA:
- Involves both tabular and textual types of information, further testing the model’s cross-modal integration capabilities.
- Complex QA formats and numerical reasoning steps provide higher challenges to evaluate the model’s comprehensive performance in handling multi-source information.
- The introduction of freeform answers tests the model’s performance in open-ended QA tasks.
Implementation Plan
Part 1: Table Filter
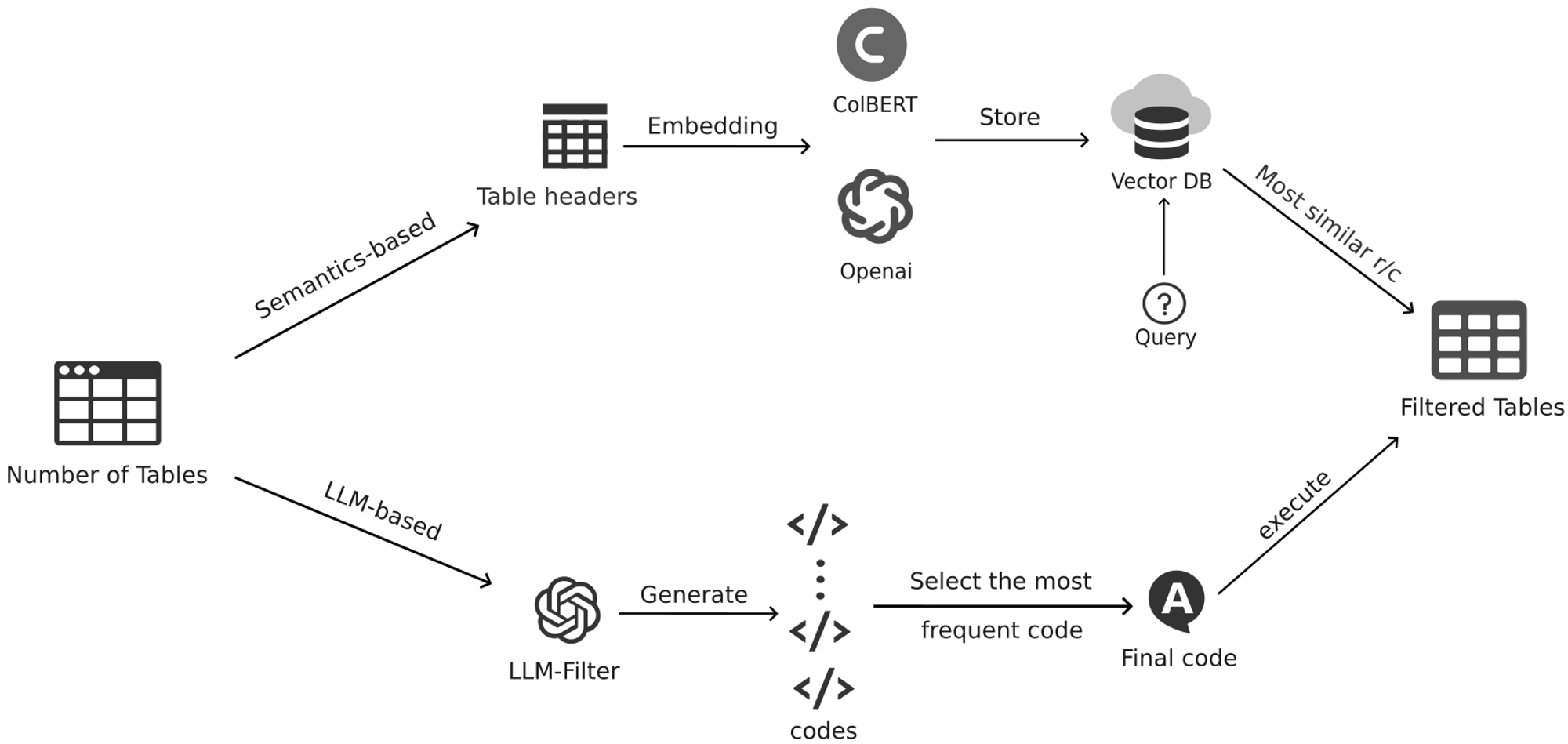
- Semantic-Based Filtering
- Generating Embedding Vectors: Generate semantic embedding vectors for each row and column in the table, as well as for the user’s query. We implemented this process in two ways:
- Vector Database Matching: Use OpenAI or other embedding models to generate embedding vectors, then calculate similarities using a vector database like FAISS, quickly returning the rows and columns related to the query.
- Fine-Grained Matching: Use the ColBERT pre-trained model to embed and match table data and queries for more fine-grained matching, selecting the most relevant rows and columns.
- Selecting Relevant Rows and Columns: Based on similarity scores, select the top k rows and columns most relevant to the query to construct new sub-tables.
- Generating Embedding Vectors: Generate semantic embedding vectors for each row and column in the table, as well as for the user’s query. We implemented this process in two ways:
- Large Language Model (LLM) Based Filtering
- Convert to String: Convert the query and table content into strings and concatenate them to form a context.
- Call GPT for Filtering: Use the GPT model to filter and extract rows and columns related to the query, generating the corresponding Python code for filtering. To improve the accuracy and consistency of code generation, we adopted a self-consistency strategy:
- Self-Consistency Strategy: Have GPT generate the code five times, selecting the most frequently generated code as the final filtering code. If the generated code versions are different, select the result from the first generation.
- Execution and Error Handling: Execute the final selected code segment to update the table. If an error occurs during code execution, capture the error message and return the original table to ensure the robustness of the process.
Challenges and Solutions in LLM-Based Filtering
In the process of table filtering, especially in the LLM-based table filter, the following major challenges exist:
Column Name Consistency Issue: GPT may misinterpret column names when generating filtering code, leading to inconsistencies between the generated code and the original table column names, causing errors. For example, ‘scheduled’, and ‘capacity (mw)’ may be misunderstood as ‘scheduled capacity (mw)’ as a single column name, or the LLM may merge multiple column names into one or incorrectly split a single column name.
Solution: To address this issue, the Prompt can explicitly provide the cleaned-up column names as parameters to be passed to GPT, ensuring that the generated code uses column names that are completely consistent with the original table. This approach can fundamentally reduce the occurrence of column name recognition errors.
Information Loss Issue: During LLM filtering, the filtered table may lose critical information needed to answer the question due to over-filtering. This can lead to inaccurate or incorrect answers being generated in subsequent answer generation due to a lack of necessary evidence.
Solution: To address this issue, a “conservative filtering” strategy can be adopted, where the LLM only filters out content that it is very certain is unrelated to the statement. If the LLM is uncertain whether some content is related to the statement, it should lean towards retaining this content. This strategy can maximize the retention of potential key evidence, ensuring that the generated answers can be based on complete information, thus improving the accuracy and credibility of the answers.
Data Type Mismatch Filtering Issue: When processing table data, especially when filtering numerical data, mismatches in data types may result in empty or inaccurate filtering results.
Solution: Even when processing numerical data, it is recommended to perform filtering using string matching. This approach can avoid filtering errors caused by data type mismatches, thereby improving filtering accuracy and reliability.
Effectiveness of Prompt Design: The design of the Prompt is crucial for ensuring that GPT accurately understands the task and generates correct filtering code. An unclear Prompt may lead to GPT generating code that does not meet expectations.
Solution: In designing the Prompt, it should be ensured that it is clear, specific, and contains sufficient context information so that GPT can accurately understand the task requirements. At the same time, the Prompt can be repeatedly tested and adjusted to find the most suitable expression, improving the accuracy of code generation.
Code Generation Consistency Issue: GPT may generate multiple different versions of the code during code generation, leading to inconsistent results.
Solution: By using the self-consistency strategy, generating multiple versions of the code and selecting the most frequently occurring version, consistency and reliability of the results can be ensured. If all generated codes are inconsistent, the first generated code can be used with error capture handling to ensure the stability of the process.
Finally, the detailed settings we used are as follows:
1 |
|
Part 2: Table Clarifier
When dealing with complex tabular data, providing clarifications can significantly enhance the understanding of the table’s content. However, selecting the appropriate clarification method is crucial. In the initial design, we attempted to use the Google API to retrieve term explanations and enhance the table content with Wikipedia documents. Specifically, in the initial design, we followed the process outlined below for clarifying the table.
Early Method Workflow
Term Clarification
- First, a large language model (LLM) analyzes the table content to identify terms that require further explanation.
- For the identified terms, the Google API is used to search for relevant explanations.
- The retrieved explanations are then appended to the table as term clarification information. This process can be implemented using the
GoogleSearchAPIWrapper()in Langchain.
Wiki Document Clarification
- Based on the table’s title, context, or header information, a Wikipedia query is constructed. For example, if the table header includes “Company Name,” “Revenue,” and “Number of Employees,” a query like “company revenue employees market capitalization” can be constructed.
- The
WikipediaRetriever.get_relevant_documents()in Langchain is then used to retrieve relevant Wikipedia documents. - Metadata, such as titles, summaries, and links, is extracted from the retrieved documents and combined with the table content as additional clarification data.
We used the following Prompt:
1 | You are an expert in data analysis and natural language processing. Your task is to help identify terms in a table that may need further explanation for better understanding. The table contains various fields, some of which might include technical jargon, abbreviations, or specialized terms that are not commonly understood by a general audience. |
Certainly! Here’s the translated content in academic English in Markdown format:
Afterward, we pass it to Lanchain, utilizing the GoogleSearchAPIWrapper() to perform retrieval, and integrate the results as clarification information.
For the Wikipedia method, we implement it as follows:
For instance, consider the following table:
| Company Name | Revenue (Million USD) | Number of Employees | Market Cap (Billion USD) |
|---|---|---|---|
| Company A | 1000 | 5000 | 50 |
| Company B | 2000 | 10000 | 100 |
| Company C | 1500 | 7500 | 75 |
We construct the query based on the table headers:
1 | "company revenue employees market capitalization" |
The retrieved information is as follows:
1 | { |
The above document metadata, combined with the table, serves as the clarification data.
Sui, Y., Zou, J., Zhou, M., He, X., Du, L., Han, S., & Zhang, D. (2023). Tap4llm: Table provider on sampling, augmenting, and packing semi-structured data for large language model reasoning. arXiv preprint arXiv:2312.09039.
This method theoretically helps us acquire rich information resources; however, in practice, it reveals some significant issues.
First, the accuracy issue of the Google API results. While retrieving term explanations through the Google API might be effective for handling certain specialized terms that usually have a unique definition, the situation becomes complicated when dealing with acronyms or polysemous words. For example, the acronym “ABC” might correspond to multiple different concepts, such as “American Broadcasting Company” or “Activity-Based Costing,” among others. In such cases, the term explanations retrieved from Google may exhibit inconsistencies, not only failing to achieve the intended enhancement but potentially causing confusion and making the results more complex and unreliable.
Second, the verbosity issue of the retrieved content. The content retrieved from Google and the documents returned by Wikipedia may be excessively verbose, containing large amounts of information related to the table content but irrelevant to the actual query needs. These verbose documents, when further processed, might negatively impact the retrieval effectiveness of the data pipeline. Most research currently focuses on feeding each query individually into an LLM or pre-trained model for processing. However, our current task differs, and this approach might lead to suboptimal results. If the documents are too long and contain excessive irrelevant information, it could reduce the accuracy and efficiency of the model, thereby affecting the overall quality of the results.
Improving and Refining the Table Clarification Strategy
Precise Optimization of the Term Clarification Module
Based on the above reasons, after extensive literature review and careful consideration, we propose the following two key requirements for table clarification information:
Clarification information must enhance the understanding of the table.
The primary goal of clarification information is to assist the model in better understanding the table content. The added information should be precise and helpful in enabling the model to more accurately grasp the structure and meaning of the table during processing, thereby improving overall comprehension.
Clarification information must improve the recall capability related to the table.
Secondly, clarification information should contribute to enhancing the model’s ability to recall content related to the table. This means that when faced with a query or analysis task, the model should be able to more effectively extract and utilize key information from the table.
In proposing these requirements, we also identified two situations that must be avoided:
Incorrect clarification information that impairs the LLM’s understanding of the table.
If the clarification information contains errors, it may lead to misinterpretation of the table by the model, thereby reducing its ability to correctly parse the table content. This not only defeats the purpose of providing clarification information but may also cause biases in the model’s output.
Excessively lengthy and redundant clarification information that hinders the model’s ability to recall relevant tables.
Lengthy or redundant information may increase the processing burden on the model, distracting it from the core content, and thus weakening the model’s efficiency and accuracy in recalling relevant table information.
Improvements to the Table Clarifier
Based on the analysis of the requirements for table augmentation information and the potential issues, we propose further improvements to optimize the method of augmenting tables. These improvements aim to ensure that the augmentation information enhances both the model’s understanding and the retrieval efficiency of relevant information, thereby avoiding common pitfalls such as misunderstandings and redundancy.
Improvements to the Term Clarification Module
For the term clarification module, we decided to directly utilize the LLM to extract and explain terms from the table, rather than relying on external retrieval through the GoogleSearchAPIWrapper. While this method may not obtain the broader comprehensive information available on the internet, the LLM is already capable of understanding most terms and abbreviations and can provide explanations in context. This approach not only improves the understanding of the table but also effectively avoids potential misleading information and redundancy issues arising from external retrieval, ensuring the precision and conciseness of the augmentation information.
Improvements to the Wiki Reference Module
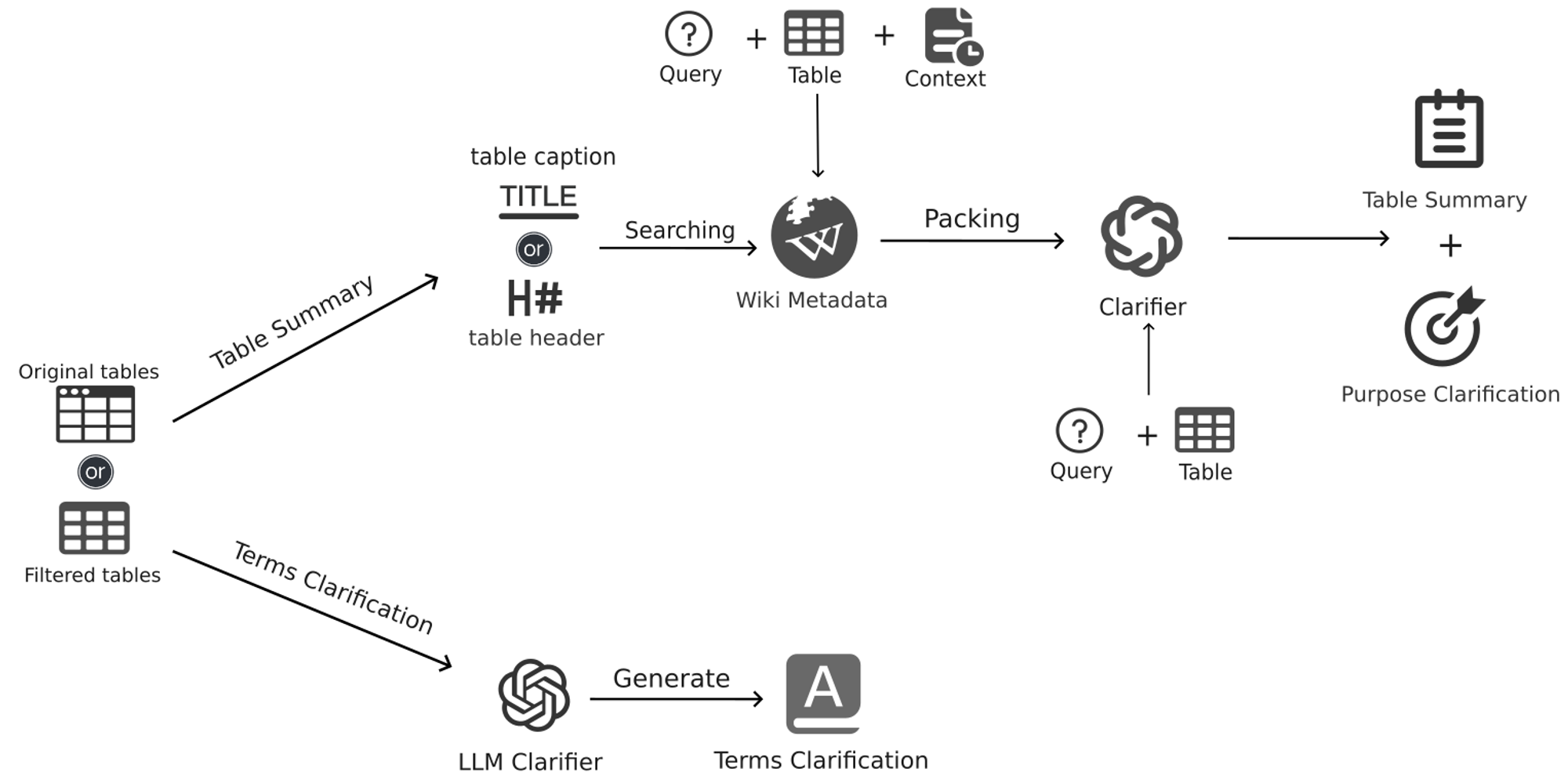
1. Clarification of Table Purpose
We introduced a new piece of clarification information, a brief explanation of the table’s purpose, i.e., what question the table is intended to answer. By generating information based on a clear statement of the table’s purpose, we can significantly improve recall rates when using ColBERT for information retrieval.
Through this method, we achieve an enhancement in the table’s recall ability, ensuring that the model can more accurately extract relevant data when faced with specific queries. The specific prompt and example usage are as follows:
1 | def generate_terms_explanation(self, table: dict, statement: str, caption: str) -> str: |
2. Optimization of Wikipedia External Information Augmentation
- Initial Retrieval:
- Wikipedia Retrieval Based on Table Title: Initially, we use the table title as a keyword to retrieve related augmentation information from Wikipedia.
- Alternative Retrieval: If the title-based retrieval fails, we use the table header information to conduct the search, providing augmentation information relevant to the table content.
- Information Packaging:
- We extract metadata from the Wikipedia data, but we do not directly incorporate this information into the clarification content to avoid redundancy.
- Instead, we package the Wikipedia metadata, query, table (including the filtered or original table), caption, and context (if available) together, and send it to the LLM for processing. The LLM will then generate a table summary based on this multifaceted information.
Key Considerations:
- Avoid Directly Revealing the Answer: When generating the summary, care should be taken to craft a guiding summary that avoids directly disclosing the answer to the question or providing an outright solution. The purpose of the summary is to help the LLM better understand and guide further exploration, rather than offering a direct solution. Additionally, directly revealing the answer may result in misleading information.
- Focus on Relevant Content: Ensure that the summary generated by the LLM includes only information relevant to the query, avoiding redundancy or unnecessary details. This helps maintain the summary’s brevity and focus.
Our detailed implementation is as follows:
1 | def get_docs_references(self, parsed_example: dict) -> dict: |
The specific prompt and example content used are as follows:
1 |
|
We have conducted in-depth consideration and optimization of the table augmentation methods. Through the aforementioned methods, we can largely ensure that when dealing with complex data, the model can more accurately understand and recall key information from the tables. By improving the term clarification module and the Wikipedia reference module, we have successfully avoided the potential pitfalls of external information, such as misleading data and redundancy, thereby enhancing the overall performance of the model in various scenarios. These improvements not only guarantee the quality of augmented information but also lay a solid foundation for the reliability and efficiency of the model in practical applications.
Part 3: Enhancing the Retrieval Process
In the retrieval process, traditional methods such as BM25, DPR (Dense Passage Retrieval), or direct vector database searches are commonly used. BM25, a classical and efficient text retrieval method, ranks documents based on the frequency of keyword occurrences. On the other hand, DPR employs a dual-tower model that uses deep learning techniques to embed queries and documents into high-dimensional vector spaces, matching them based on approximate similarity. Both methods perform well in simple query scenarios, but they may have limitations in precision and efficiency when handling complex and diverse queries. Vector database retrieval, leveraging efficient vector similarity search libraries like Faiss, meets the demands of large-scale data retrieval.
However, these methods may lack sufficient retrieval accuracy when faced with complex queries or table-like data. Therefore, we ultimately chose to enhance the TableRAG system using ColBERT. This decision was based not only on ColBERT’s unique innovations and advantages but also on its demonstrated efficiency and accuracy in practical applications. Currently, ColBERT can be easily integrated into the RAG pipeline via RAGatouille, and Llamaindex provides integration with this repository, making its application even more convenient.
Innovations and Advantages of ColBERT
Innovations
- Late Interaction Framework: ColBERT reduces online query computation by decoupling the encoding of queries and documents, with similarity calculation performed after encoding. This allows for precomputing document representations, significantly improving computational efficiency.
- MaxSim Operation: ColBERT uses the MaxSim operation to evaluate the relevance between queries and documents. It sums the maximum cosine similarity or L2 distance between each query embedding and the document embeddings, a simple yet effective approach.
- Shared BERT Encoder: By sharing a BERT encoder and adding special tokens ([Q] and [D]) before input, ColBERT saves computational resources while retaining contextual understanding.
- Document Segmentation and Filtering: Unrelated information, such as punctuation, is filtered out to reduce computational and storage burdens.
- Vector Similarity-Based Retrieval: Leveraging vector similarity search libraries like Faiss, ColBERT efficiently retrieves documents from large collections end-to-end.
Advantages
- High Computational Efficiency: Precomputing document representations and the late interaction mechanism drastically reduce the computational load during query processing, improving speed by two orders of magnitude.
- High Space Utilization: Through normalization and dimensionality reduction, ColBERT effectively reduces storage space requirements, enhancing feasibility in practical applications.
- Strong Scalability: ColBERT’s architecture is designed to handle large document collections without sacrificing accuracy, particularly excelling in efficient pruning operations during vector similarity searches.
- End-to-End Retrieval Capability: ColBERT can directly retrieve from large document collections, improving system recall rates and accuracy.
Improvements in ColBERTv2
In ColBERTv2, these advantages are further enhanced. Specifically, the introduction of residual compression mechanisms and denoising supervision significantly reduces storage needs while improving training effectiveness. Additionally, ColBERTv2 optimizes the indexing and retrieval process, achieving more efficient candidate generation and passage ranking, further enhancing retrieval performance.
Practical Applications in the Retrieval Process
In our TableRAG system, ColBERT is used not only to rerank the pre-retrieved document set but also to directly improve system recall and accuracy through its end-to-end retrieval capabilities. To further optimize the quality of retrieval results, we have introduced a rerank mechanism that reorders the initially retrieved document set. This mechanism helps refine and enhance the relevance and accuracy of the results after the initial retrieval.
Specifically, when using ColBERT for queries, the system first preprocesses and encodes all documents in the table, generating efficient vector representations. During the query process, ColBERT uses these pre-generated document vectors to quickly identify the most relevant documents through the MaxSim operation. Subsequently, the rerank mechanism further refines the ordering of these initial results, ensuring that the final documents presented to the user most closely align with the query intent.
Our tests show that using ColBERT combined with the rerank mechanism not only significantly improves retrieval accuracy but also further optimizes query response times. Through this multi-layered retrieval and ranking approach, we can ensure high-precision retrieval results while avoiding the high computational costs and long response times associated with traditional methods.
In conclusion, by integrating ColBERT and the rerank mechanism into our TableRAG system, we effectively utilize augmented information during the retrieval process. This enhancement strategy not only boosts the system’s computational efficiency and storage utilization but also, through its innovative retrieval and ranking mechanisms, significantly increases retrieval speed and result relevance without sacrificing accuracy. As a result, our system can quickly and accurately return the most relevant information when handling complex table queries, thereby significantly enhancing user experience and overall system performance.
Part 4: Enhancing Input Formats
Optimization of Table Formats Passed to LLMs
In the process of table augmentation and retrieval, the format in which tables are passed to large language models (LLMs) is crucial to the final processing effectiveness. Existing research has explored different table conversion methods and compared their impact on the performance of LLM-based question-answering systems. These methods include Markdown format, template serialization, traditional pre-trained language model (TPLM) methods, and direct text generation using large language models (LLMs). Studies have shown that the performance of table conversion methods varies across different paradigms.
In the paper Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data, the authors compared the performance of different table conversion methods on hybrid datasets, particularly their effects on LLM-based question-answering systems:
- Markdown Format: Representing table content using Markdown format.
- Template Serialization: Using predefined templates to convert tables into text.
- Traditional Pre-trained Language Model (TPLM) Methods: Fine-tuning models such as T5 and BART for table-to-text tasks.
- Large Language Model (LLM) Methods: Generating text in one-shot using models like ChatGPT.
The study concludes that:
- In the Data-Specific Feature Transfer (DSFT) paradigm, table-to-text conversion methods using language models (TPLM and LLM) performed best.
- In the Retrieval-Augmented Generation (RAG) paradigm, the Markdown format exhibited unexpected efficiency, though LLM methods still performed well.
Optimization of Input Formats
Based on the above research, we selected two table formats to be passed to LLMs in our experiments to further optimize system performance:
- HTML Format: HTML format provides a clear, structured representation that allows the model to accurately understand the hierarchy and relational content of the table. This format is suitable for scenarios requiring the preservation of complex table structures, especially in multi-dimensional or nested table contexts where HTML format can effectively convey the semantic information of the table.
- Markdown Format: Markdown format, known for its simplicity and human readability, is widely used in various text representation tasks. Research indicates that in the RAG paradigm, Markdown format not only effectively represents table content but also enhances model processing efficiency. Therefore, we adopted the Markdown format in our experiments to evaluate its performance in practical applications.
By adopting these two formats, we aim to maximize the potential of LLMs in table processing tasks. The structural advantage of the HTML format and the concise efficiency of the Markdown format offer flexible choices for different scenarios, ensuring that table content can be accurately understood and efficiently processed by LLMs, thereby further improving the overall performance of table-based question-answering systems.
The implementation of this format optimization strategy is not only theoretically supported by existing research but has also been practically validated in our experiments, providing a solid foundation for subsequent system development. We will continue to explore other possible formats to further optimize the way tables are passed to LLMs, ensuring that the system maintains excellent performance in various complex scenarios.
Evaluation Experiments
1. Control Experiment
The purpose of the control experiment is to evaluate the performance changes when gradually adding various modules to the baseline model. The specific design is as follows:
- Baseline: The original model without any additional modules, serving as a reference standard.
- Filter: Gradually adding different filtering modules to the baseline model.
- Semantics-based: This is further divided into two sub-parts:
- ColBERT: Adding the ColBERT semantic similarity comparison module.
- OpenAI Embedding Model: Adding the OpenAI Embedding Model for semantic similarity comparison.
- LLM-based: Adding an LLM-based filter.
- Semantics-based: This is further divided into two sub-parts:
- Clarifier: Gradually adding different clarification strategies to the baseline model.
- Term Exp.: Adding the term expansion module.
- Table Summary: Adding the table summary module.
- Exp. & Summary: Adding both the term expansion and table summary modules.
- Formatter: Gradually adding different formatting
methods to the baseline model.
- String: Using string formatting.
- Markdown: Using Markdown formatting.
- HTML: Using HTML formatting.
- Retriever: Testing different retrieval strategies on the baseline model, particularly evaluating the impact of using the rerank mechanism with the ColBERT model to reorder results.
- BM25: Using BM25 for retrieval.
- DPR: Using DPR for retrieval.
- ColBERT: Using ColBERT for retrieval, also evaluating whether reranking the retrieval results impacts the outcome.
- Consist.: Testing the performance of the model after adding a consistency module.
2. Ablation Experiment
- Filter: Exploring the impact of different filters on model performance.
- Semantics-based: Further divided into two sub-parts, where the modules using ColBERT and the OpenAI Embedding Model for semantic similarity comparison are removed.
- LLM-based: Removing the LLM-based filter module.
- Clarifier: Evaluating the contribution of different clarification strategies to the model.
- Term Exp.: Removing the term expansion module.
- Table Summary: Removing the table summary module.
- All Removed: Removing all clarification-related modules.
- Formatter: Testing the impact of different formatting methods on the model.
- Markdown: Removing Markdown formatting.
- HTML: Removing HTML formatting.
- Consist.: Testing the model’s performance without the consistency module.
Retriever Evaluation
To evaluate the recall rates of different retrievers, the following experiments were conducted on four datasets, with and without table summaries:
- BM25: Traditional TF-IDF retriever.
- ColBERT:
- No rerank: Using the initial retrieval results generated by ColBERT.
- With rerank: Reordering the initial retrieval results.
- DPR: A dense vector retriever based on deep learning.
- Faiss Vector Database: An efficient vector retrieval database.
Acknowledgments
I would like to express my sincere gratitude to the authors of the paper “Tap4llm: Table provider on sampling, augmenting, and packing semi-structured data for large language model reasoning” for providing valuable insights that influenced some of the ideas presented in this article.
Copyright Notice
© Wuyuhang, 2024. All rights reserved. This article is entirely the work of Wuyuhang from the University of Manchester. It may not be reproduced, distributed, or used without explicit permission from the author. For inquiries, please contact me at yuhang.wu-4 [at] postgrad.manchester.ac.uk.
Reference
- Zhang, T., Li, Y., Jin, Y. and Li, J., 2020. Autoalpha: an efficient hierarchical evolutionary algorithm for mining alpha factors in quantitative investment. arXiv preprint arXiv:2002.08245.
- Li, L., Wang, H., Zha, L., Huang, Q., Wu, S., Chen, G. and Zhao, J., 2023. Learning a data-driven policy network for pre-training automated feature engineering. In The Eleventh International Conference on Learning Representations.
- Chen, Z., Chen, W., Smiley, C., Shah, S., Borova, I., Langdon, D., Moussa, R., Beane, M., Huang, T.H., Routledge, B. and Wang, W.Y., 2021. Finqa: A dataset of numerical reasoning over financial data. arXiv preprint arXiv:2109.00122.
- Chen, W., Zha, H., Chen, Z., Xiong, W., Wang, H. and Wang, W., 2020. Hybridqa: A dataset of multi-hop question answering over tabular and textual data. arXiv preprint arXiv:2004.07347.
- Zhu, F., Lei, W., Huang, Y., Wang, C., Zhang, S., Lv, J., Feng, F. and Chua, T.S., 2021. TAT-QA: A question answering benchmark on a hybrid of tabular and textual content in finance. arXiv preprint arXiv:2105.07624.
- Babaev, D., Savchenko, M., Tuzhilin, A. and Umerenkov, D., 2019, July. Et-rnn: Applying deep learning to credit loan applications. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 2183-2190).
- Ye, Y., Hui, B., Yang, M., Li, B., Huang, F. and Li, Y., 2023, July. Large language models are versatile decomposers: Decomposing evidence and questions for table-based reasoning. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 174-184).
- Cheng, Z., Xie, T., Shi, P., Li, C., Nadkarni, R., Hu, Y., Xiong, C., Radev, D., Ostendorf, M., Zettlemoyer, L. and Smith, N.A., 2022. Binding language models in symbolic languages.arXiv preprint arXiv:2210.02875.
- Robertson, S. and Zaragoza, H., 2009. The probabilistic relevance framework: BM25 and beyond. Foundations and Trends® in Information Retrieval, 3(4), pp.333-389.
- Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D. and Yih, W.T., 2020. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J. and Wang, H., 2023.
Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997. - Lu, W., Zhang, J., Zhang, J. and Chen, Y., 2024. Large language model for table processing: A survey. arXiv preprint arXiv:2402.05121.
- Jiang, J., Zhou, K., Dong, Z., Ye, K., Zhao, W.X. and Wen, J.R., 2023. Structgpt: A general framework for large language model to reason over structured data. arXiv preprint arXiv:2305.09645.
- Sui, Y., Zou, J., Zhou, M., He, X., Du, L., Han, S. and Zhang, D., 2023. Tap4llm: Table provider on sampling, augmenting, and packing semi-structured data for large language model reasoning. arXiv preprint arXiv:2312.09039.
- Bian, N., Han, X., Sun, L., Lin, H., Lu, Y., He, B., Jiang, S. and Dong, B., 2023. Chatgpt is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models. arXiv preprint arXiv:2303.16421.
- Lin, W., Blloshmi, R., Byrne, B., de Gispert, A. and Iglesias, G., 2023, July. LI-RAGE: Late Interaction Retrieval Augmented Generation with Explicit Signals for Open-Domain Table Question Answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (pp. 1557-1566).
- Li, X., Chan, S., Zhu, X., Pei, Y., Ma, Z., Liu, X. and Shah, S., 2023. Are ChatGPT and GPT-4 general-purpose solvers for financial text analytics? A study on several typical tasks. arXiv preprint arXiv:2305.05862.
- Chen, W., Wang, H., Chen, J., Zhang, Y., Wang, H., Li, S., Zhou, X. and Wang, W.Y., 2019. Tabfact: A large-scale dataset for table-based fact verification. arXiv preprint arXiv:1909.02164.
- Aly, R., Guo, Z., Schlichtkrull, M., Thorne, J., Vlachos, A., Christodoulopoulos, C., Cocarascu, O. and Mittal, A., 2021. Feverous: Fact extraction and verification over unstructured and structured information. arXiv preprint arXiv:2106.05707.
- Iyyer, M., Yih, W.T. and Chang, M.W., 2017, July. Search-based neural structured learning for sequential question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1821-1831).